NER上分利器:实体边界重定位
1. 背景
在做命名实体识别的时候,模型识别错误的很大一部分原因是边界识别不好。因此如何将命名实体的边界进行重定向是进一步提升NER性能的利器。其中一种方法是可以利用词典和规则的方法进行边界重定向,如前文提到的《利用前后向算法》,第二种方法可以用下文提到了指针网络进行边界重定向。此方法参考于《Don’t Eclipse Your Arts Due to Small Discrepancies: Boundary Repositioning with a Pointer Network for Aspect Extraction》。
2. NER错误类型
该方法可以处理两种错误类型,
- 一种是模型识别的实体短了,少预测了两个字。
- 一种是模型识别长了,多预测了两个字。
因此我们的想法就是将少预测的部分补全,将多预测的部分去除。而使用的方法就是重新训练一个指针网络识别新的实体边界。
Ground-truth表示模型应该识别的边界。
3. 具体样例
他爱吃苹果派。
目的是为了识别商品实体词:苹果派
4. 实体边界重定位方法
步骤1:实体抽取模型的训练
4.1.1 模型结构
训练命名实体识别(NER)模型,这里可以是任何一种模型。可以使用常见的 CNN+Bi-LSTM+CRF ,也可以是 BERT+CRF 总之,在这个步骤里面训练的模型可以是任意一个NER模型。比如BERT+SoftMax。
4.1.2 模型输入输出
输入是一段 sentence。输出是实体列表。比如:【苹果】。
步骤2:边界重定向模型的训练
假设第一步的模型输出了NER结果是:【苹果】
4.2.1 模型结构
BERT的双句分类模型结构。
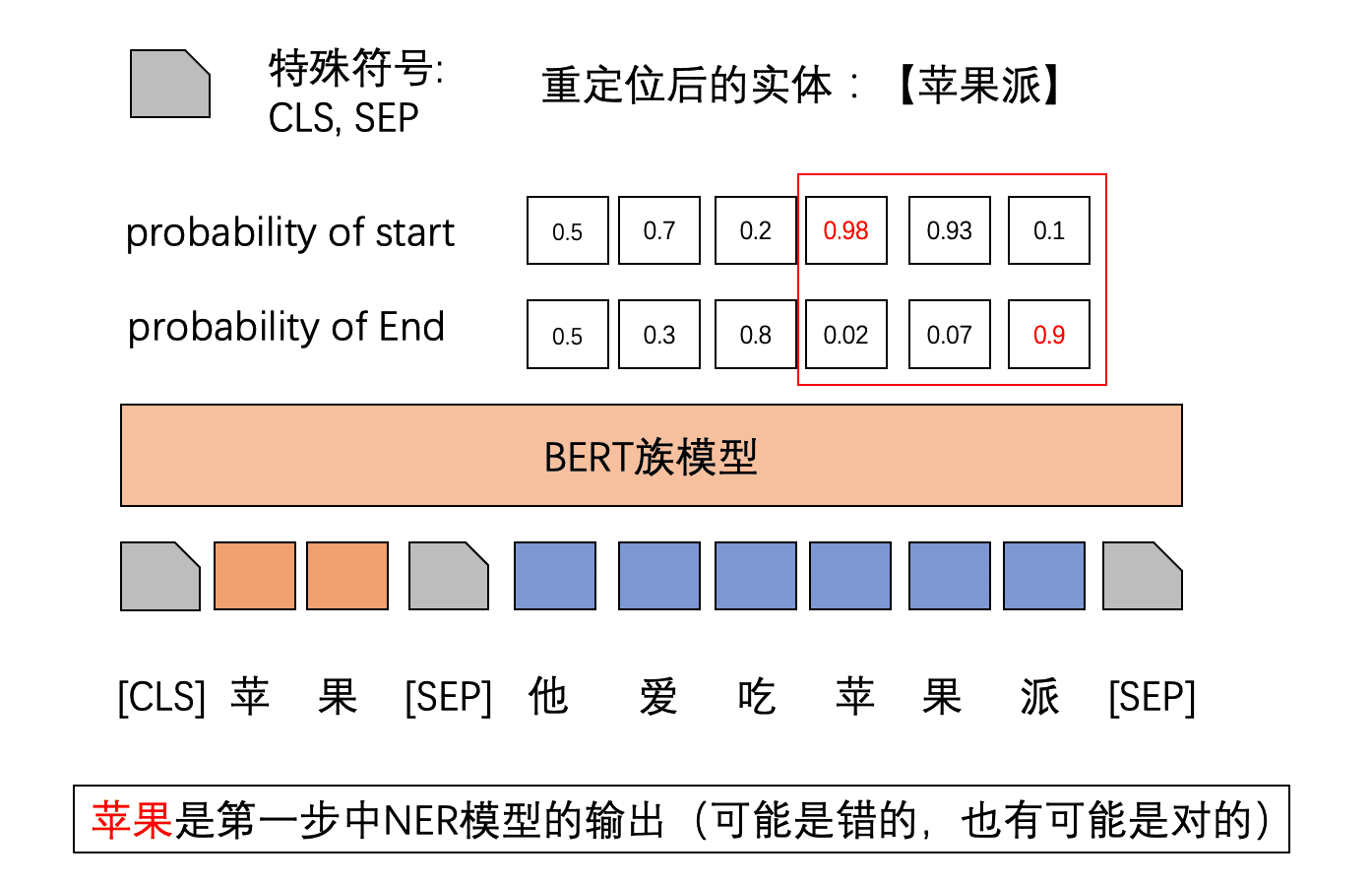
4.2.2 模型的输入输出
模型的输入: 回顾BERT双句分类,我们的sentence1应该改成步骤一里面的输出的实体。sentence2就是原来的输入的sentence。假设步骤一中一共输出了两个实体,那么我们就构建两个训练样本。
预测正确和错误的实体都用于构建训练样本。
模型的输出: 对于这里,模型是对边界进行重定位,因此就是对 sentence2中的每一个字预测它start和end的概率,然后取start和end最大的中间那一部分当做最终预测的实体。
4.2.3 模型优化目标
这里使用是负log对数函数,当然使用其他的loss也是可以的。
4.2.4 细节(重点重点)
Question:对于步骤2,最重要的就是如何构建 实体样本,也就是说在步骤二中应该如何获得sentence1,sentence1应该在那里获得。 Answer:候选实体的负样本通过步骤一的模型产生。具体做法是:生成一个字典(map),当真实的实体当做key, value 是一个负样本列表。
每一个真实的实体都对应一个负样本列表。 {'true entity': ['wrong entity1', 'wrong entiry2']} 。把每一个训练的epoch中产生的wrong entity都加入到对应的true entity里面。wrong entiry应该和 true entity 有重合。
比如“苹果”和“苹果派”之间有重合,而“爱吃”和“苹果派”之间没有重合,因此“苹果”应该当做训练样例,而“爱吃”不应该当做负的训练样例。
Reposition 模型的正样例就是:<CLS> 正确的实体 <sep> 要判断的sentence <sep>。
步骤3:测试样例的推理预测
模型训练部分已经讲完了,预测时候就只需要将要预测的句子输入到步骤一种的实体抽取模型中。然后对输出的实体构造样本,送入到步骤二中的实体边界重定向模型中。最后将每一个句子对应的实体都找出来,就完成了 通过实体边界重定向提高NER性能 。
5. Reference
[1] Don’t Eclipse Your Arts Due to Small Discrepancies: Boundary Repositioning with a Pointer Network for Aspect Extraction