Transition-based Directed Graph Construction for Emotion-Cause Pair Extraction (中文介绍)
背景
随着互联网技术的迅速普及,社交媒体迅速成为用户观点交流和情绪表达的重要平台,人们越来越习惯于在社交平台上发表对某个热点事件的观点,或者在电商网站中针对某一商品进行评论,这些社交媒体文本往往蕴涵了大量的情绪表达。如何从这些文本信息中识别和分析用户的情绪表达,进而挖掘情绪产生以及改变的原因,不仅可以准确地把握用户的意向以及情绪的走向,还可以辅助商家了解消费者的需求。
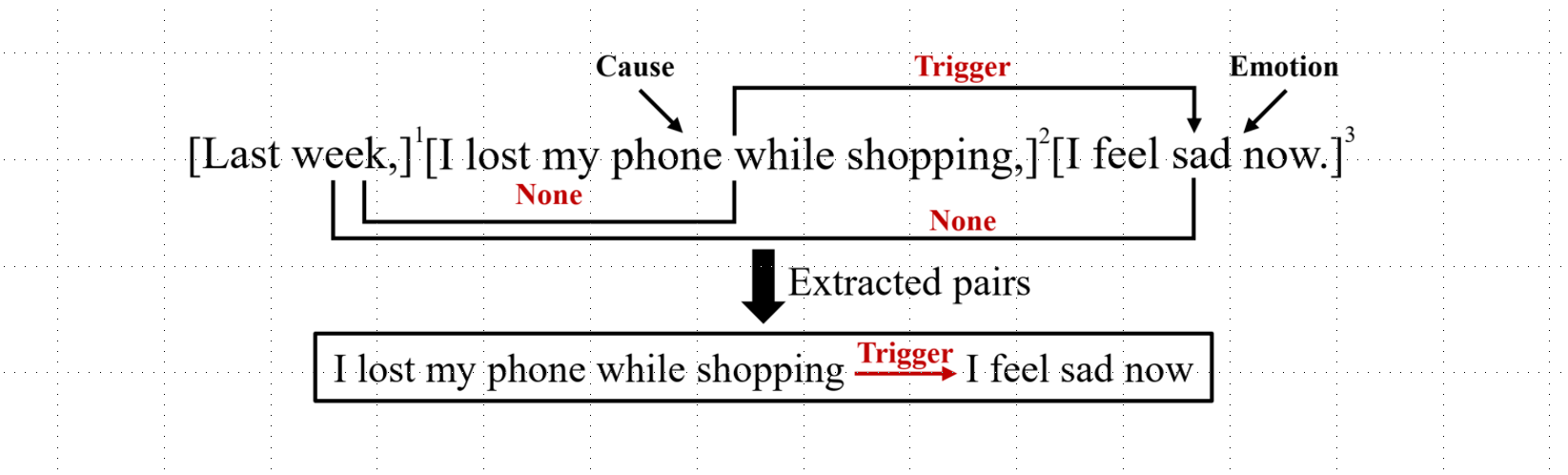
现有的情绪原因分析研究主要专注于挖掘给定情感表达的原因,这就需要人们事先对文本进行情绪的标注,因而难以在实际应用中推广。为了解决这个问题,南京理工大学的夏睿团队提出了情感-原因对抽取(Emotion-Cause Pair Extraction, ECPE)任务,旨在抽取未标注文本中所有的情感子句以及相对应的原因子句。以下图为例,该文本一共包含三个子句,其中第三个子句是表达了一种 Sad 的情绪,第二个子句是触发该情感的原因,因此可以在该文本中找到一个情感-原因对{“昨天我手机掉了”触发“我现在很难过”}。
针对该任务,夏睿等人基于流水线模型将该任务分解为两个子任务:首先,识别文本中所有的情感子句以及原因子句;然后将识别出的情感子句集合与原因子句集合做笛卡尔乘积,并训练分类器将没有因果关系的情感-原因对过滤。然而,这种基于流水线的模型通常存在误差传递的问题,即前一子任务如果不能识别出正确的情感或者原因子句,则后一任务难以得到正确的情感-原因对。为了缓解上述问题,哈尔滨工业大学(深圳)的徐睿峰课题组首次将该任务整合为递增式的有向图构建问题,并提出了基于状态转移的联合学习模型,该模型能够同时提取情感子句以及相应的原因子句。实验结果表明,该方法相比于当前最优模型在F1值上有6.7%的提升。相关研究成果《Transition-based Directed Graph Construction for Emotion-Cause Pair Extraction》被自然语言处理顶级会议ACL 2020接受。
任务模型简介
首先给出任务定义,给定文本 , 情感-原因对抽取任务旨在提取文本中所有的{情感,原因}:。由于该任务定义在子句级别上,因此在和在论文中分别表示情感子句和原因子句。
为了缓解基于流水线的模型存在误差传递的问题,本文提出了一种基于状态转移的情感-原因对抽取框架,将情感-原因对抽取视为单一任务并整合到类似解析的有向图构造过程中。 该框架从输入序列中从左到右的逐步构造和标记有向边,并使用丰富的非局部特征对子句片段进行评估。 整体模型框架下图所示。 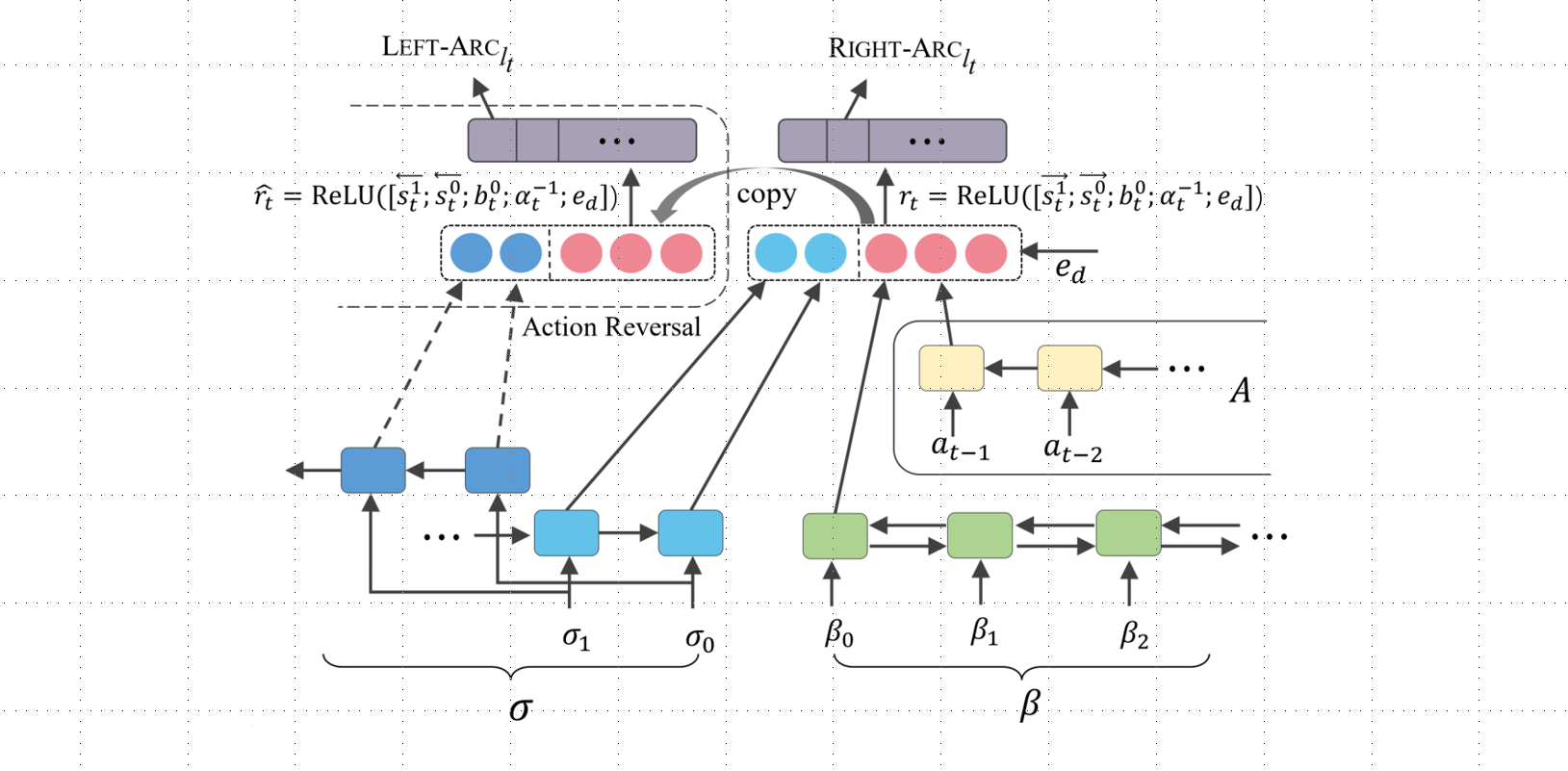
有向图的构建
假设有向图表示为:。其中 V 表示图中节点并与文本中的子句一一对应,R 表示有向边: ,代表节点(子句)与节点(子句)之间的连接关系。针对情感-原因对抽取任务,论文中定义的连接关系为:节点i与节点j之间的连接为 ,其中表示节点之间是否存在情感因果关系。 表示节点j是情感子句,节点i是相应的原因子句; 则说明节点j是情感子句,但节点i不是它对应的原因,其他与最终结果无关的节点之间不存在连接关系。同时,由于一个子句可以既是情感又是其相应的原因,因此自连接在论文中是被允许的。
针对该有向图建模问题,论文提出了一种基于状态转移的解析模型。解析过程中的每个状态可以用一个五元组表示,,其中是一个栈,用于存储处理过的子句序列,是一个列表,用于存储待处理的子句序列,两者存储的子句序列可以不连续。E和C分别是情感和原因集合,R是在解析过程中产生的有向边的集合,所有的历史动作将会被存储在列表A中。
动作定义
在基于转移的系统中,动作集的定义起着至关重要的作用且通常由要解决的问题所决定。根据情感-原因对抽取任务的特点,论文中一共定义了六种动作,如表1所示。 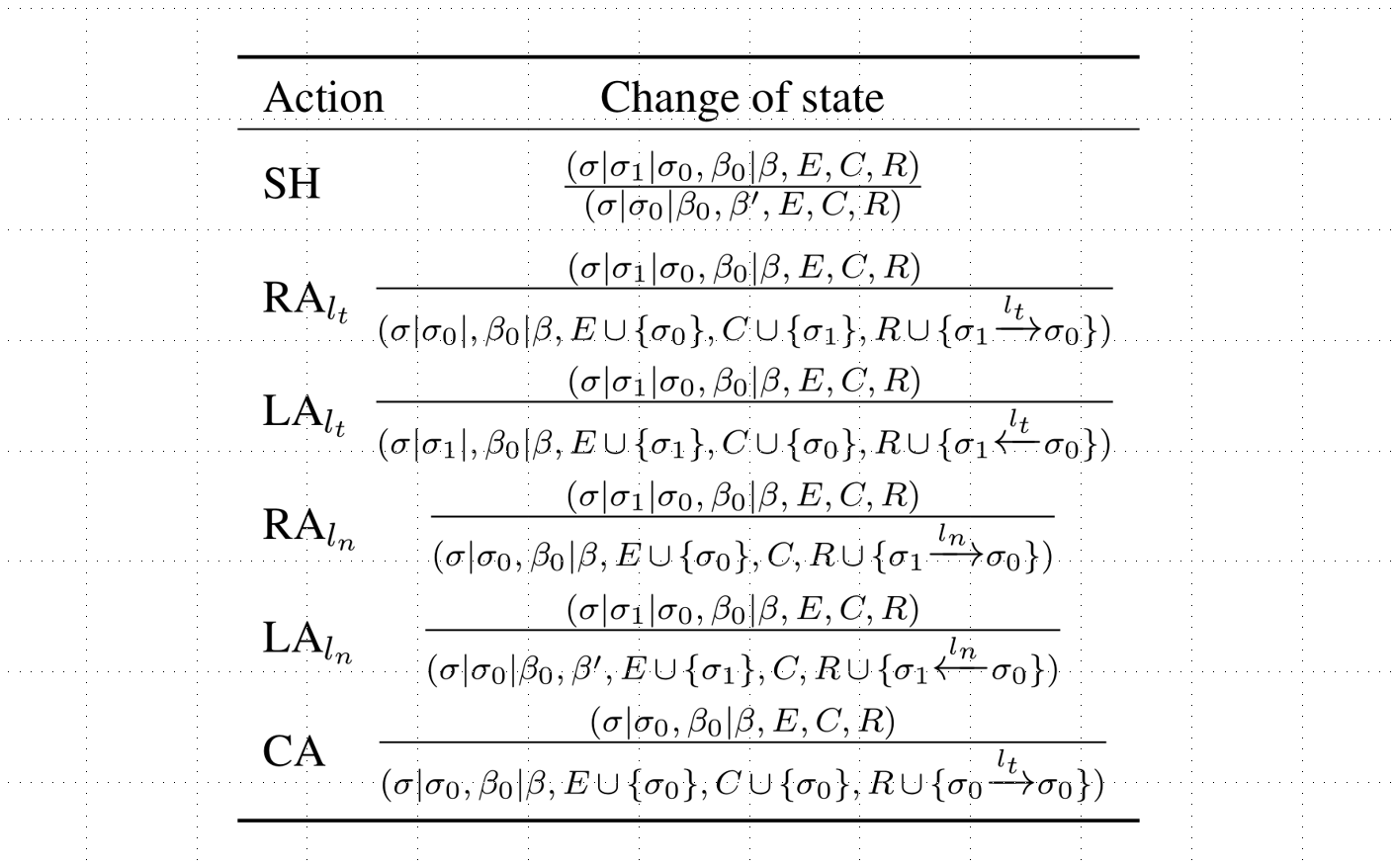 上图是论文中定义的转移动作集。论文使用 表示σ(从右向左),β和A(从左向右)中元素的下标。即σ中顶部两个元素可被表示为(β和A同理)。
上图是论文中定义的转移动作集。论文使用 表示σ(从右向左),β和A(从左向右)中元素的下标。即σ中顶部两个元素可被表示为(β和A同理)。
其中SH表示将β中的第一个元素压入σ的栈顶。 表示有一条指向的右连接边并标记为,同时弹出到C中,复制放入E中。同理,则表示有一条从指向的左连接边并标记为,并复制放入E中,将弹出并放入C中。 动作则表示有一条右连接边从指向 并标记为,表示不是情感的对应原因,那么应该弹出只复制到E中。则说明有一条左连接从指向并标记为,这里只复制到E中,但并不将弹出,因为可能是β中中某个情感子句的原因,因此需要将送入栈顶。CA则表示有一条自连接边并标记为,意味着需要将同时复制到E和C中。
为了保证在解析过程中,每一个状态都是合法的,论文对一些动作进行了限制。例如:RA和LA动作都需要保证在σ中至少有两个元素,另外如果栈顶顶部的两个元素都是情感子句,即中和都是情感,那么应该选择的动作是。需要注意的是,由于CA动作可能与其它动作有冲突,比如是其自身的原因同时也是的原因,这就与相冲突。为此,论文将CA与其他动作分开并训练一个单独的二分类器进行判断。当解析过程开始时,在每个时间步t,系统根据σ中顶部两个元素之间的关系决定将要采取的动作,直至解析完成。
任务转化
基于上述的转移系统,假设模型的输入是文本序列,输出则是动作序列 ,因此该任务可以视为搜索最优的动作序列的问题,即
在每个时间步t,其输出都依赖于当前时间步的状态以及以往的动作序列:
其中表示时间步t对应的动作,则表示系统根据动作更新后的状态。 假设代表在时间步t系统用于预测动作概率的特征表示,则:
其中和都是可以学习的参数,A(S)表示当前系统状态下合法动作的集合。最后,模型的整体优化函数可以被写为: 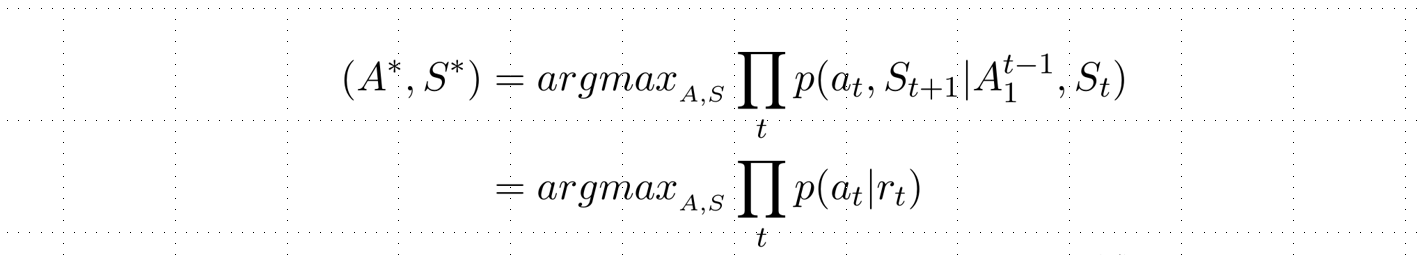
可以看到,ECPE任务被转化为了基于转移的动作预测任务。为了有效解码,在解析过程终止之前,系统贪婪地选择最大概率的动作。
子句的表示
论文首先使用 BERT获得每个子句的表示,即对每个子句前后分别加上特殊标签[CLS]和[SEP],得到模型输入:, 然后使用BERT进行编码得到:。最终使用[CLS]的表示作为整个子句的表示。
其他状态的表示
同时,为了捕获子句间的相互依赖关系,论文使用LSTM对其进行建模。考虑每个时间步t,在解析过程中一共有三个部分需要进行编码(),分别是,以及历史动作序列。针对,为了建模两种方向上子句间的依赖关系,论文使用双向LSTM生成特征表示:
同理可得:
针对历史动作序列,论文首先将每个动作映射到低维稠密空间,然后使用单向LSTM进行编码,得到:
为了挖掘情感-原因对之间的相对距离信息,论文将其相对距离也进行了随机编码并在整个训练过程中保持不变,记为。在每个时间步t,系统的状态表示即为上述表示的组合。
动作反转
此外,论文根据ECPE任务的特点提出了动作反转。例如:图1中的例子,如果以从左往右的顺序读(见下图顶部),原因子句“I lost my phone while shopping”位于情感子句“I feel sad now”的左边,此时对应的动作应为。但是,如果换个视角,以从右向左的顺序读(见下图底部),原因子句“I lost my phone while shopping”位于情感子句“I feel sad now”的右边,此时对应的作为被反转为。也就是说,和应该被视为不同的特征从而预测不同的动作,而不是简单的相拼接。 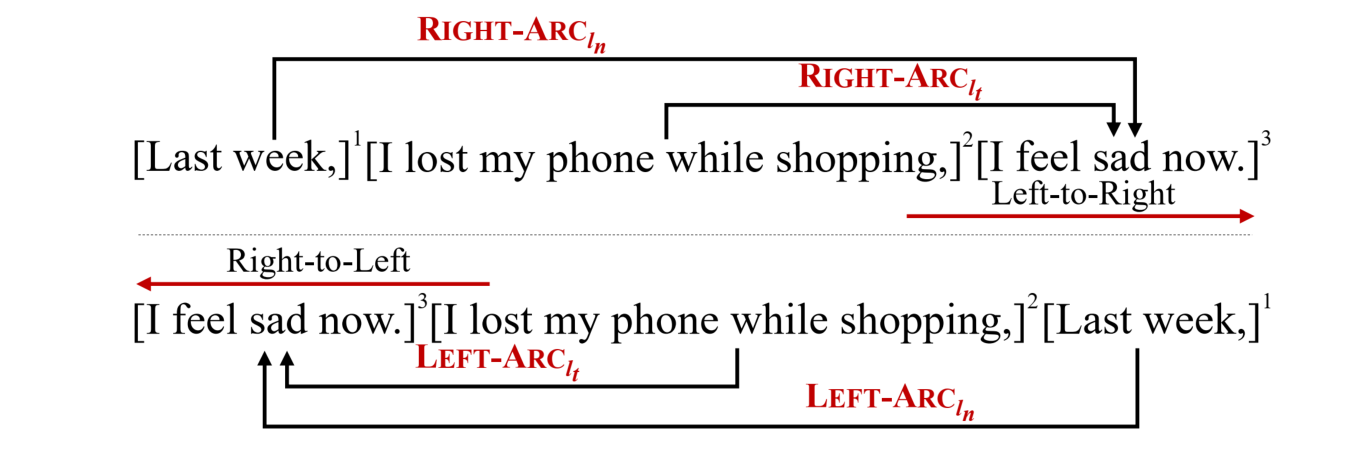 上图是动作反转示意图。
上图是动作反转示意图。
基于上述的观察,最终得到特征表示为以及 分别为:
其中上标0和1分别表示σ和β第一个和第二个元素表示,-1表示动作序列A的最后一个动作表示。因此,模型的损失函数被修正为: 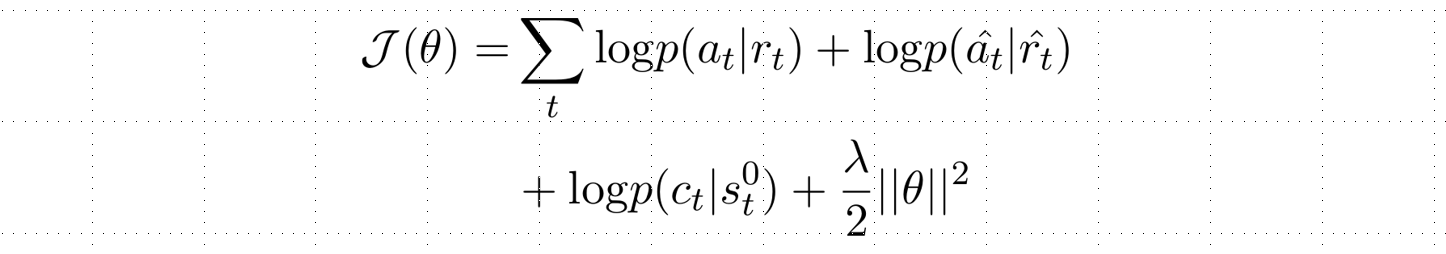 其中 ̂是反转后的动作,而则是当前系统采取动作CA的概率,θ表示模型的所有参数,λ表示L2正则的系数。注意,在测试阶段,只有和用于预测下一步采取的动作。
其中 ̂是反转后的动作,而则是当前系统采取动作CA的概率,θ表示模型的所有参数,λ表示L2正则的系数。注意,在测试阶段,只有和用于预测下一步采取的动作。
实验结果
主实验分析
为了验证该模型的有效性,论文在EMNLP2016情感原因数据集上进行了实验,实验结果见下面的主实验表格。根据实验结果可以看出,论文提出的模型在三个任务均取得了最优的性能,尤其在情感-原因对抽取的任务中比当前最优方法在F1值上提升6.7%,证明论文提出的模型能有效的完成ECPE任务。从实验结果还可以看出,论文提出的模型使用BERT对子句编码能达到最优效果,但使用LSTM进行编码也能超过当前最优方法。但如果去掉转移过程,效果则会下降很多,这进一步验证了论文提出的基于转移模型进行情感-原因对抽取的有效性。 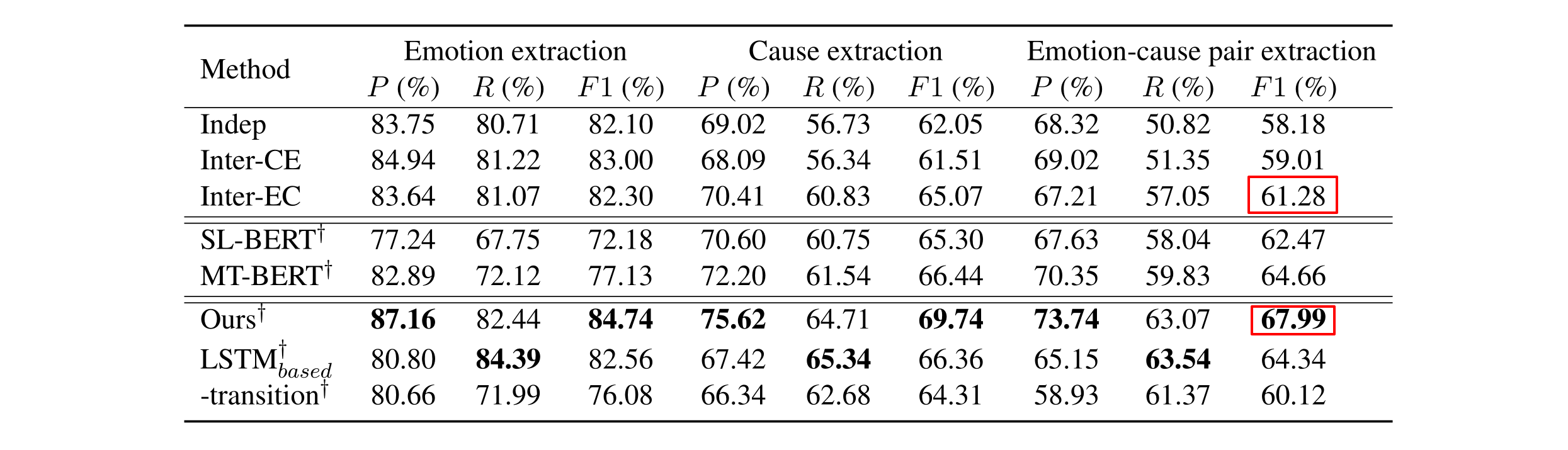
消融实验分析
此外,下表为消融实验记录标,实验结果展示了特征表达中各个部分的重要性。其中动作反转、待处理的β信息,动作历史序列等都对模型有正面效果。尤其需要注意的是如果不使用LSTM去捕获子句间的依赖关系,模型性能表现下降的幅度最大。同时,栈顶元素之间的相对距离信息也对动作预测起了非常重要的作用。 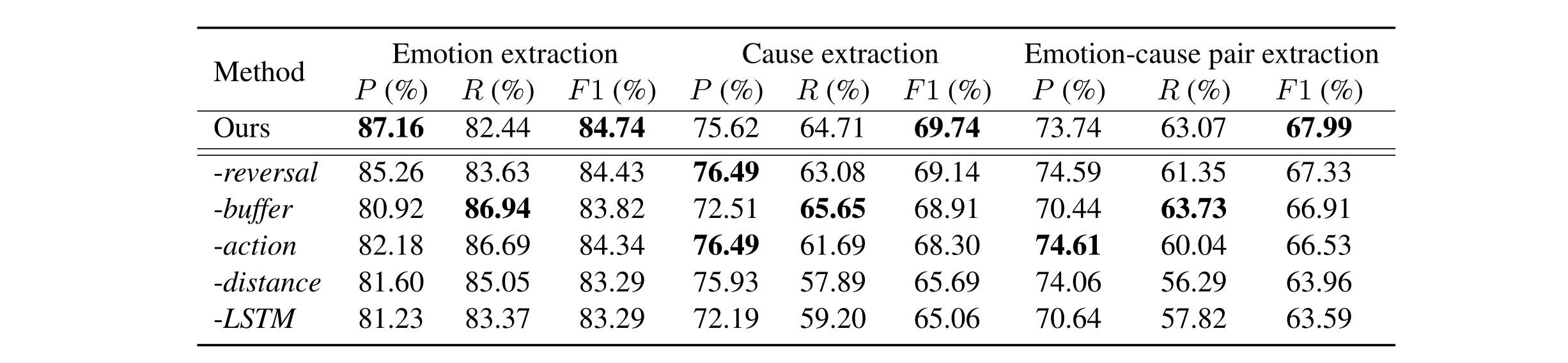
方法可行性分析
论文同样对于不能被基于转移的模型完全抽取情感-原因对的伪样例进行了分析,主要为了分析基于转移方法理论上的可行性,考虑图4中的两个伪样例。 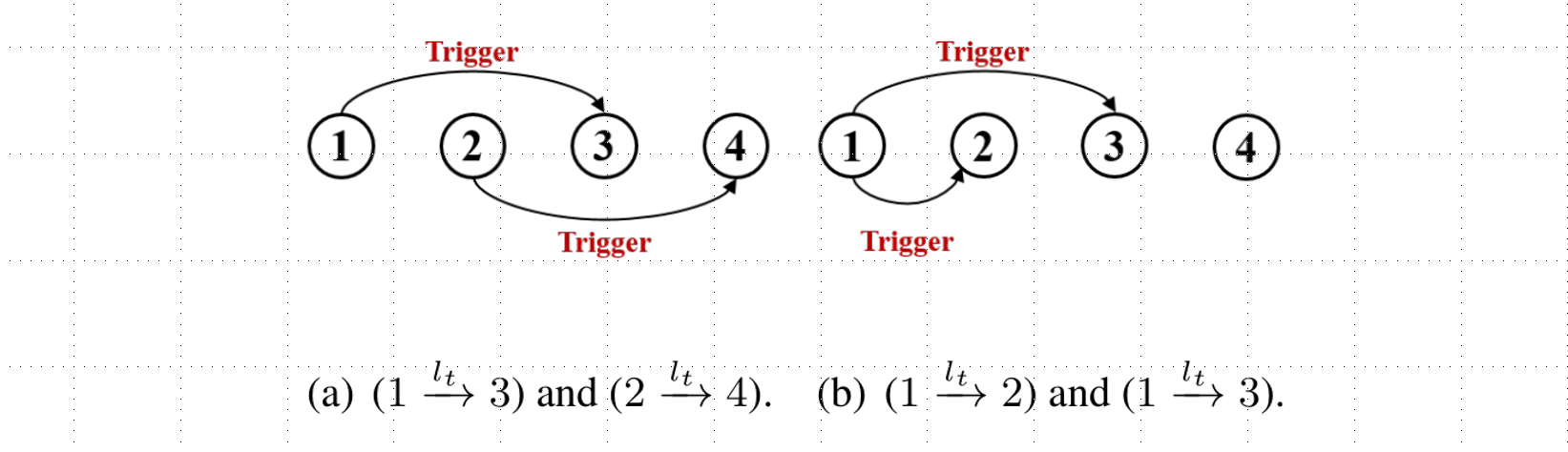
针对上图(a)和上图(b)两种情况,利用Transition-Based模型进行解析都不能覆盖到所有的情况,具体解析分析见论文5.4小节。在以上两种情况中,该模型均不能抽取文本中所有的情感-原因对。根据上述观察,一个核心的问题是论文中定义的动作集能够覆盖多少涉及情感-原因转移的情况。针对这个问题,论文设计实验证明了该模型在F1上能够覆盖98.5%的情况,即该模型在F1值中的上限为98.5%。
动作反转的有效性
最后论文中进行了动作反转的错误分析,结果见下图,统计结果显示在训练数据中只占有0.45%,因此模型对该动作的预测效果最差,而通过动作反转能很好地增强模型对少部分动作的预测。图5表明对于的识别得到了正确率从0提升到了58.8%。这是由于动作反转不仅更加符合人类的认知与模型的结构,同时也相当于增加了一倍的训练数据,相当于进行了隐式的数据增强。 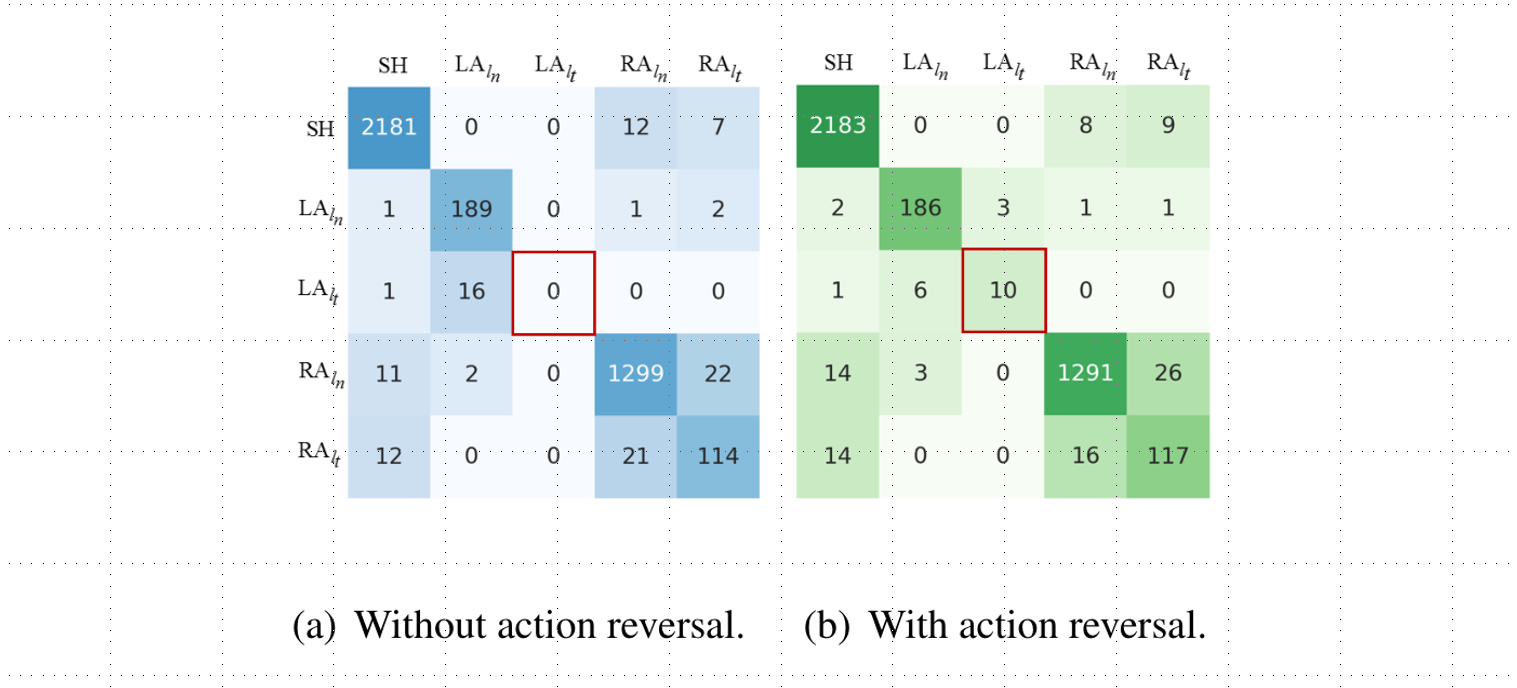 图片上显示的是测试集上的混淆矩阵。纵坐标表示系统预测的动作,横坐标表示真实的动作。
图片上显示的是测试集上的混淆矩阵。纵坐标表示系统预测的动作,横坐标表示真实的动作。
总结
本文工作主要关注情感-原因对的抽取任务,首次以端到端的方式将该任务转化为了有向图的构建问题,并提出了一种新的基于状态转移的架构,使得模型具备同时抽取未标注文本中的情感子句以及相应原因子句,从而有效的缓解了误差传递问题。在标准数据集上的实验结果证明了本文提出的模型的优越性和鲁棒性。
该介绍文由Chuang Fan师兄和我共同完成。该介绍文有较多的简化,更多的细节可以参考原文。
Reference
[1] 论文可获得的时候将进行更新