DeepSeek-GRM:Inferene-time Scaling 的 Generalist Reward Model(通用奖励模型)
1. 结论(take away)
Training Scaling 和 Inference Scaling 在 Base-Model 都取得了巨大的成功。那么在强化学习(Reinforcement Learning, RL)过程中需要的 Reward-Model(RM) 是不是也可以通过 Inference-Time Scaling 来优化 RM 呢?因此 DeepSeek 团队提出一种方法叫做:Self-Principed Critique Tuning (SPCT) 的方法来训练一个通用型的 RM(Generalist RM)。
RL 在推理模型中取得了巨大的成功,如 OpenAI 的 O系列、DeepSeek R系列(DeepSeek-R1),但这些模型都采用了 Rule-Base Reward Model,因此 Reward Model 具有一定的局限性,在很多场景不够通用,因此本文的 DeepSeek-GRM 是旨在利用 SPCT 的方式来训练一个通用型的 Reward Model,并且能够很好得 Inference-Time Scale,以此得到一个在通用任务(非数学、代码等有精确 Reward)也能有很好效果的模型。
2. 前提(Preliminaries)
2.1 RM 模型训练分类
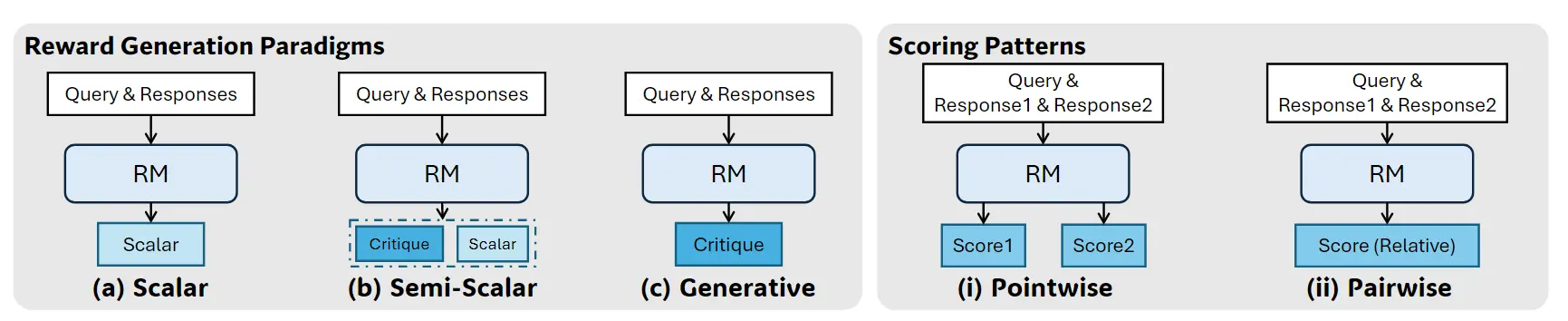
这里的分类非常的清晰,先分成两个大类:(1)打分模式(Scoring Patterns),分为 Pointwise, Pairwise;(2)生成打分的模式:Scalar(标量数值型),Semi-Scalar(半数值型),Generative(生成式)。
先对输入进行区分(Scoring Patterns)包含两种类型的输入:
- (i)Pointwise,输入是一条样本(或多个样本),但是要对每一个样本都输出对应的分数。这里解释一下为什么 pointwise 的 Scoring Patterns 可以支持多种输入形式?原因为:训练完之后,你的输入可以是一条样本,也可以是两条样本,也可以是多条样本,而下方的 pairwise 形式的 Scoring Pattens 训练完之后,只能给成对的样本评估,如果要支持多个、单个样本,则需要其他的操作。
- (ii)Pairwise,输入要是成对的样本,输入是一个值。假设是两个样本 a, b,那么输出是一个值,大于0 表示 a 好,小于0表示 b好;或者直接输出 a / b 来表示 a 好还是 b 好。
然后可以对模型的输出方式(Reward Generation Paradigms)进行区分,
- (a)Scalar:让模型一个 Head 数出一个浮点数
- (b)Semi-Scalar:先让模型一个 Head 输出一段分析(Critique),然后再用另外一个 Head 输出一个浮点数(或者直接计算某 token的 logit 值)
- (c)Generative:模型只有一个 Head,这个 Head 是通过生成的方式输出 Critique 以及最终的分数,最终的分数要自己抽取出来。
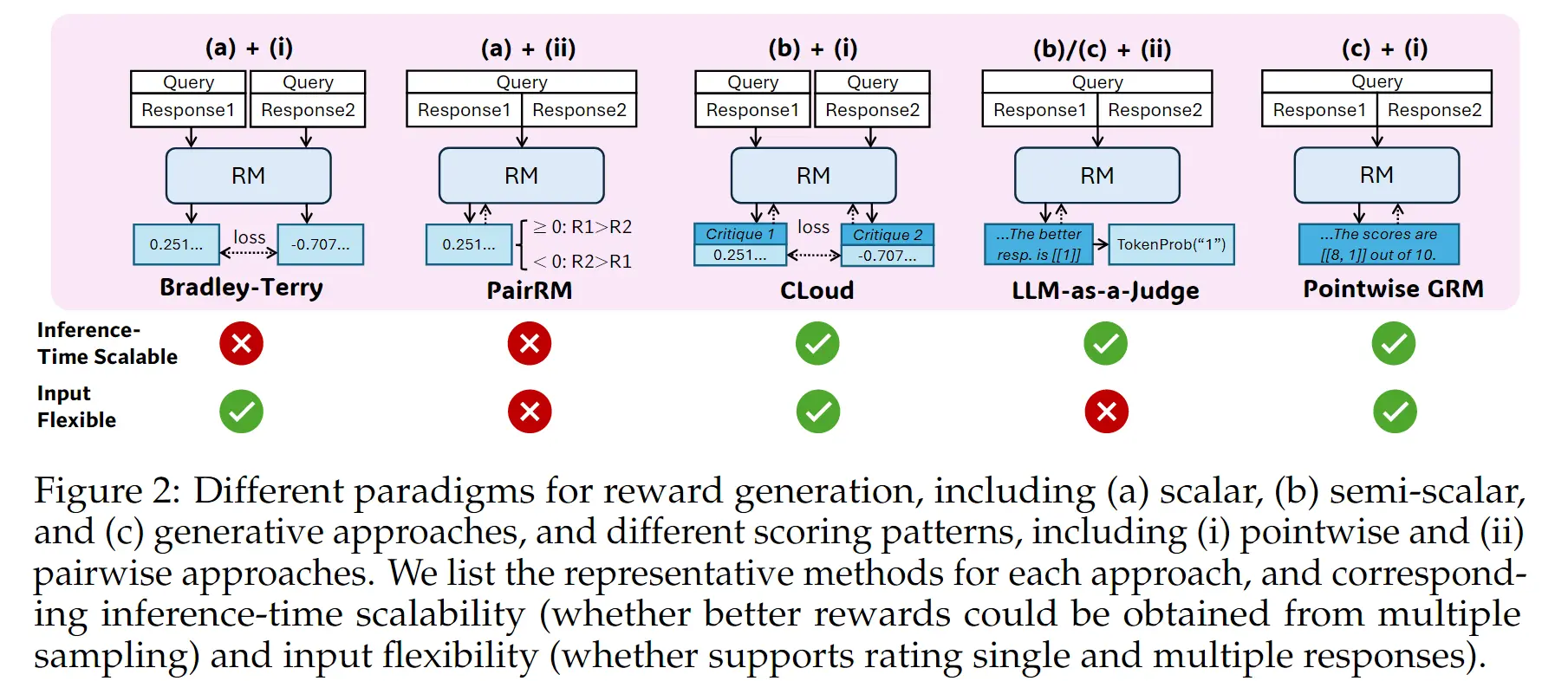
然后我们可以对此进行组合:
- (a) + (i)。没有思维链,多次推理结果都是一样的,因此没法 Inference-time Scaling。这里说的 Bradley-Terry 指的是: ,因此 Loss 可以定义成 pairwise loss, ,N 指的是数据集中的样本。
- (a) + (ii),模型输出的是 >0 / < 0 浮点数,因此也不 Scaling,训练 loss 是 Pointwise Loss。
- (b) + (i),这里因为有 Critique 的存在,每次采样都会有不同的结果,所以可以 Scaling。
- (b/c) +(ii),可以 Scaling,但是训练完之后只能成对输入。
- (c) + (i),通过生成的方式生成【critique 和 每个样本的 Score】,然后自行解析抽取结果。
但是从实际的结果结果来看,(c) + (i) 在 inference-time scaling 的效果要好于 (b) + (i),具体见下图的绿色线(CLoud),多次采样提升不明显,所以最终采用了 (c) + (i),也就是 PointWise-GRM。 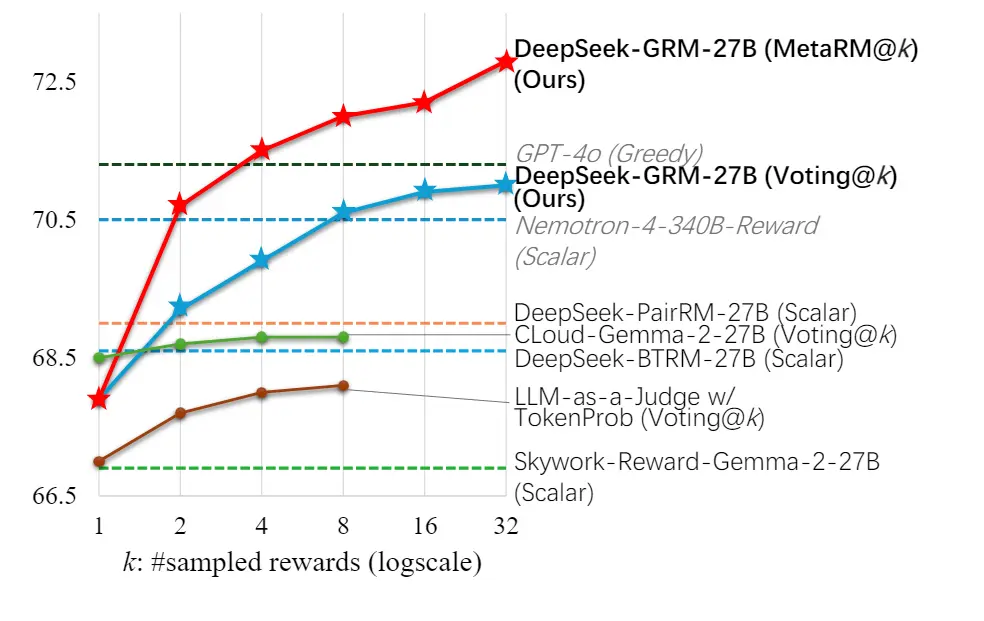
2.2 Principle可以提升RM效果
前面提到过,部分领域可以有精确的规则,比如数学、代码,但是针对于一些通用的领域,比如角色扮演、写作等,评判的规则就会变得更复杂、并且通常都没有一个固定的标准答案(golden truth),因此我们可以指定一些准则(principles)来进行打分。
当然这些准则可以是模型自己生成的。下面解释一下这个表格,以 GPT4o-2024-0806为例,Gemma-2-27B-it 同理,从表格的数据可以看出:
- 2 / 3 行对比,增加了自我增加的评估准则(principles)对于指标没有什么提升(效果差不多)。
- 2 / 4 行对比,通过一些过滤规则,相对于没有规则有一定的提升。3 / 4 行对比也同样说明如此。
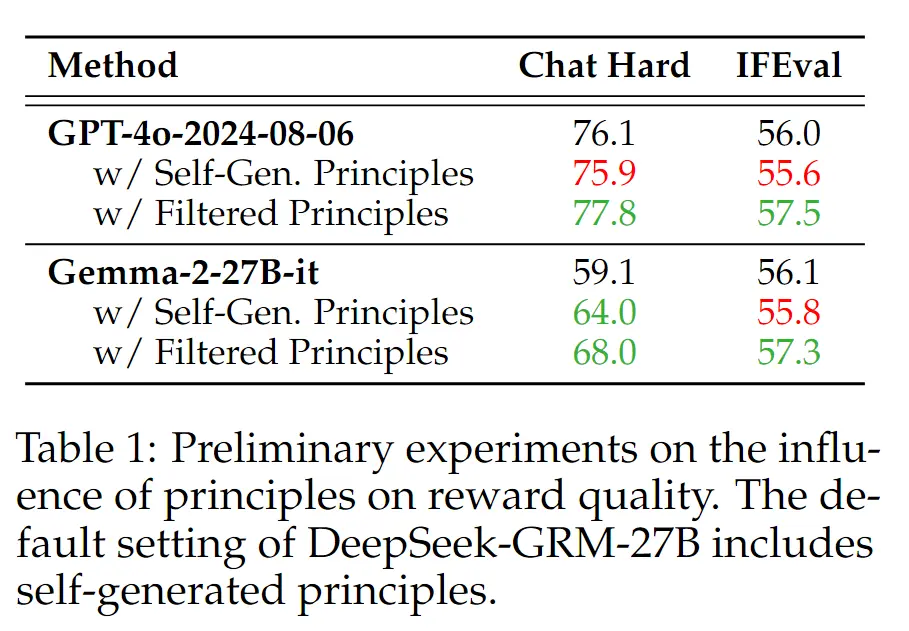
上面的结果可以让我们得出结论:经过筛选的自我生成的评估准则可以提升 Reward-Model 的效果。
3. Self-Principled Critique Tuning(SPCT)
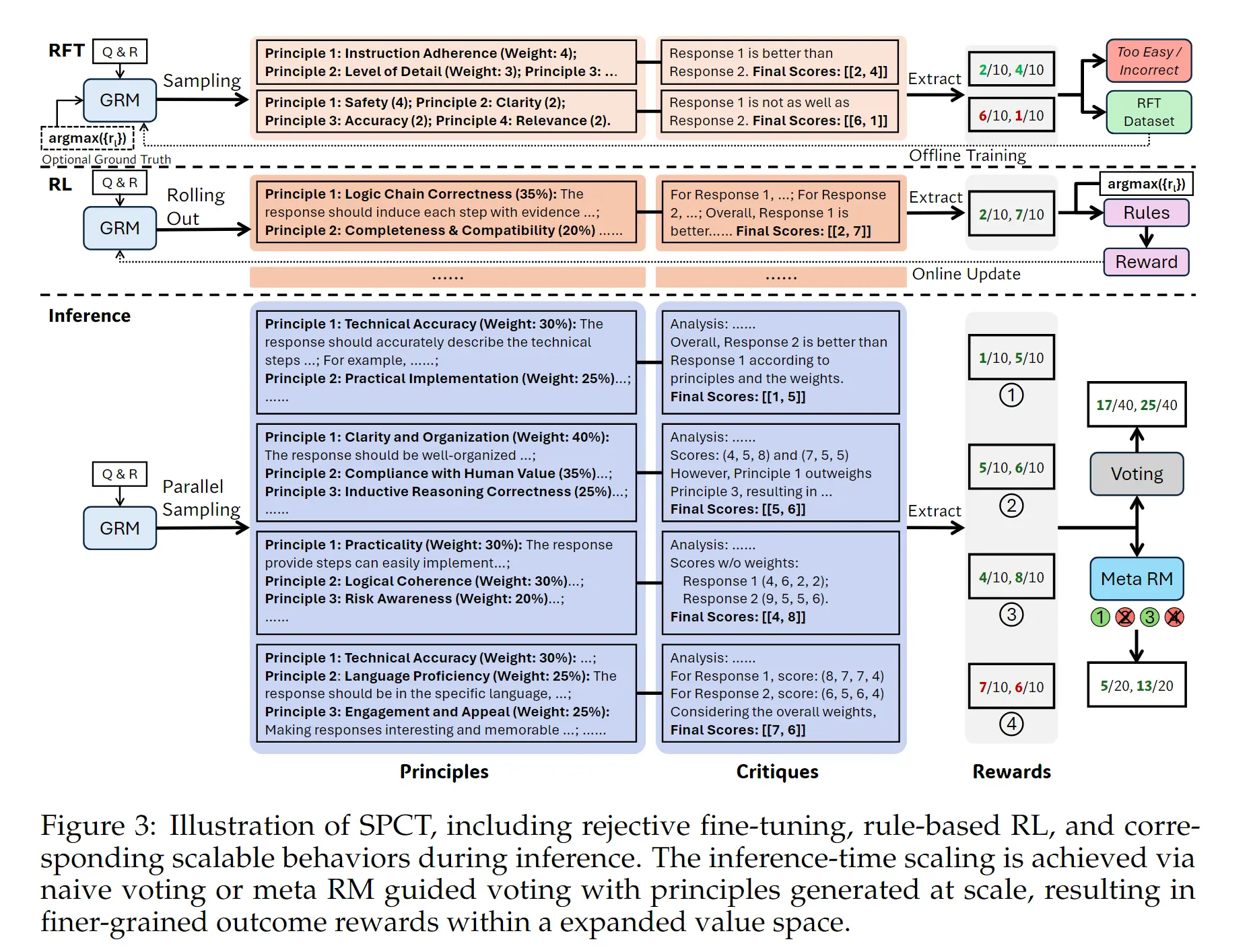
从这个图可以看出,SPCT 一共包含两个大部分部分
- 训练
- RFT(rejective fine-tuning)作为冷启动
- rule-based online RL(reinforcement learning) 用于强化模型生成评估准则(principle)和推理批判(critique)的能力,后面都用 principle 和 critique 表示。
- 推理
- 通过 inference-time scaling 的方式增加 RM 的最终能力。
3.1 训练
3.1.1 RFT (Reject fine-tuning)
前面提到了,一个通用的 GRM 要做到输入自由,所以我们最终采用的是 Pointwise-GRM,用同一个模型生成 principle 和 critique。样本构造方式如下:
- 给定一个 , 是一句话(包含模型的 instruction 和 output)。有 个 golden 结果(response 1/2 的打分),以及 表示 GRM 预测的结果,这里格式样例为每一个: "principle 1: xxx, principle 2: xxx。Analysis: xxxx, ,response 1 、2 FinalScore: [2, 3]",我们可以抽取出 final score,然后与 进行对比。对于每一个 我们都要过 次 GRM(因此也就会有多个结果,但是我们要过滤掉一些结果,这个过滤的过程就是我们拒绝采样的过程。
- 首先我们会把预测结果和 golden label 不一致的过滤
- 其次会过滤过于简单的样本,也就是在 次采样的过程中,都和 golden label 结果一样的样本。
- 具体的过滤要求是,对于有多条 response 输入的样本(如上面样例中的 response 1/2 就是有 2 个 response 输入),那么最终要求人工标注的最优 response 具有最大的 score;而如果 response 只有一条,那么要求预测的奖励值等于 goden label。( 表示对于第 条 response 的 score)
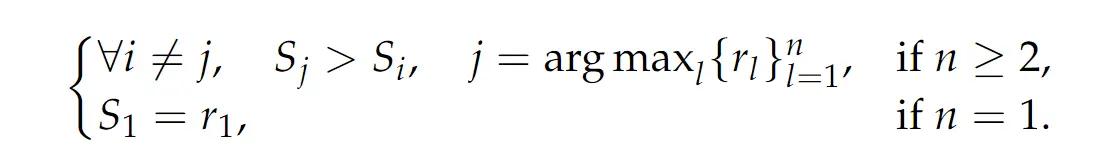
- 上面的看似美好,但是没有考虑到,GRM 有限次采样的过程中,可能无法生成符合 golden label(具体某一条response 好以及打分),因此会加入一条人工打分最大的 response 到 prompt 中,这条样本被叫做 hinted sampling,如果使用 hinted sampling 则只采样一次,实验结果发现 hinted sampling 的样本 Critique 结果更短(这样效果可能受限),因此只适合做冷启动,更多的效果提升还是需要 online RL
3.1.2 online RL
强化学习部分因为使用 rule-based reward,因此细节反而相对比较简单。具体是使用 GRPO 算法做训练,输入是:一个 (instruction) 以及 (n 条 response),输出是:GRM 生成的 principle 和 critique,然后抽出去对应的分数,计为 ,下面的公式总结起来就一句话:预测对了给 1 分,预测错了给 -1 分,没有其他的格式分。 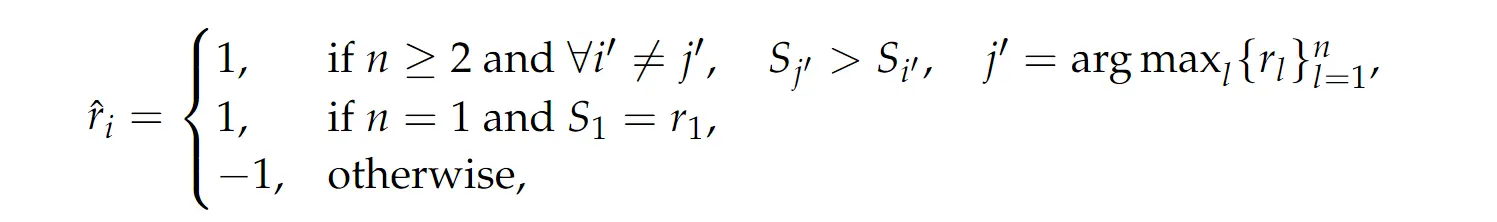
其他细节:KL 散度约束的系数比 DeepSeek-R1 更大,然后设置 GRPO 中 rollout 次数为 4 来平衡效率和效果。
3.2 推理
SPCT 最重要的初衷是什么?是【inference-time scaling】。因此推理的时候有两个方式来 Scaling 达到提升效果的目的。
- Voting with Generated Rewards。具体解释为:推理的时候 sample 多条结果,那么就会有多个结果的 score,把每个 response 的结果加起来作为最终的结果。
- Meta Reward Model Guided Voting。也就是说不是对多次采样的 Score 直接加起来,因为有时候 GRM 可能生成一些质量低的 principle 和 critique,而是通过训练一个 meta rewrd model 来引导投票过程。具体就是训练一个二分类,表示当前的 principle 和 critique 是否要被用于投票,也就是过滤掉一些低质量的采样结果。比如 Figure 3 中的 meta RM 就过滤掉了 2 4 两个结果,只用 1 3 用于投票。一般设置保留一半的采样结果。
4. 实验结果
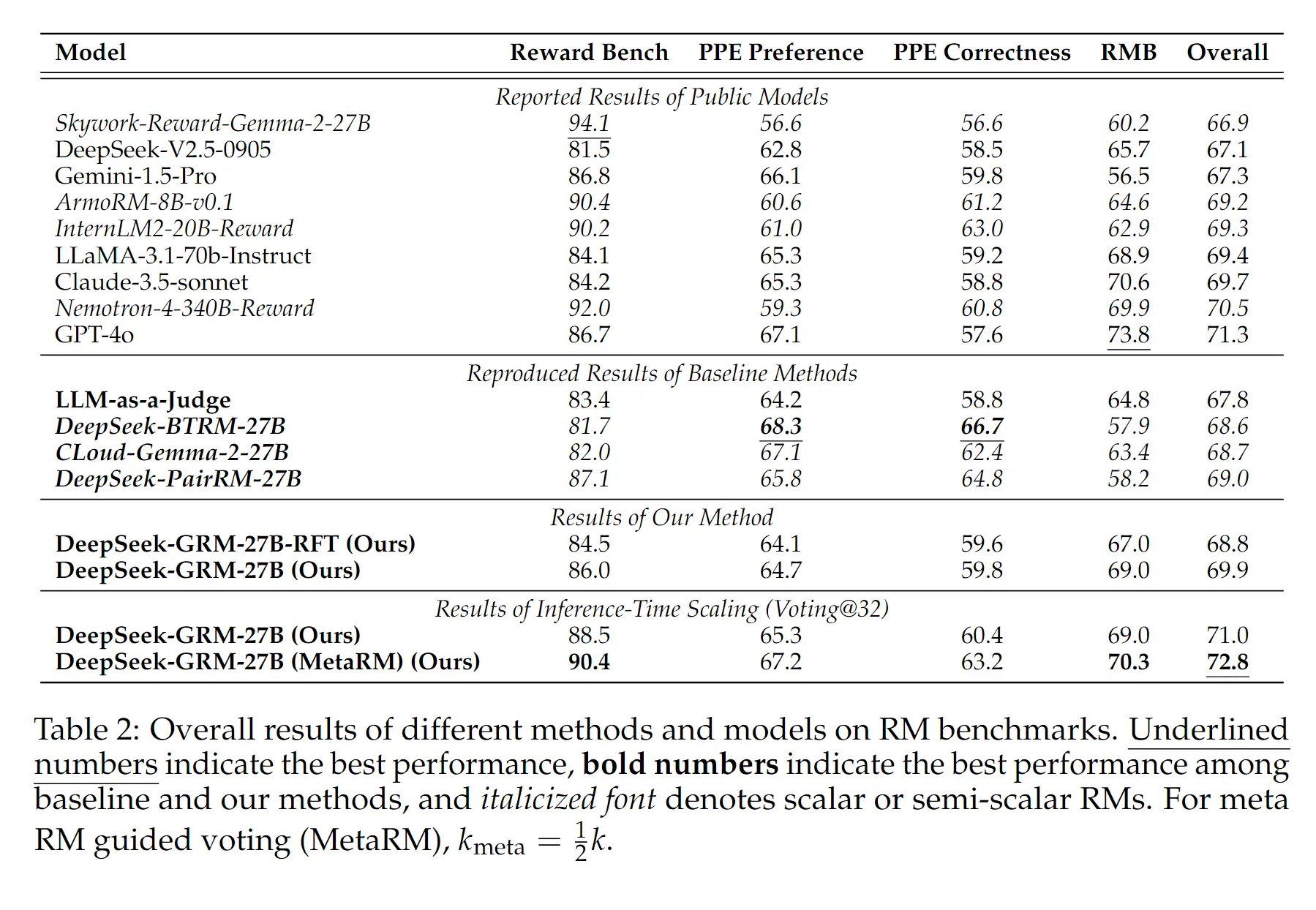
4.1 主实验分析
- 27B的 spct-GRM模型比 340B 大模型效果还要好,并且不像 scalar 和 semi-scalar 的模型一样比较大的 bias(比如 ppe 任务,可验证奖励任务就表现更好)。
- 相对于 LLM-as-a-Judge 的方式,带有 spct 的GRM 因为有 principle 的生成,GRM相对更好一些。
- 整体上说就是:SPCT 提升了 GRM 在通用任务的评估能力,并且具有更少的领域偏差(不一定非得是可验证奖励的领域才表现好)。
4.2 Inference Scaling
Inference-time Scaling,Voting 从 1 -> 32,效果逐步提升,并且 MetaRM 会进一步带来效果,这个无需多说。
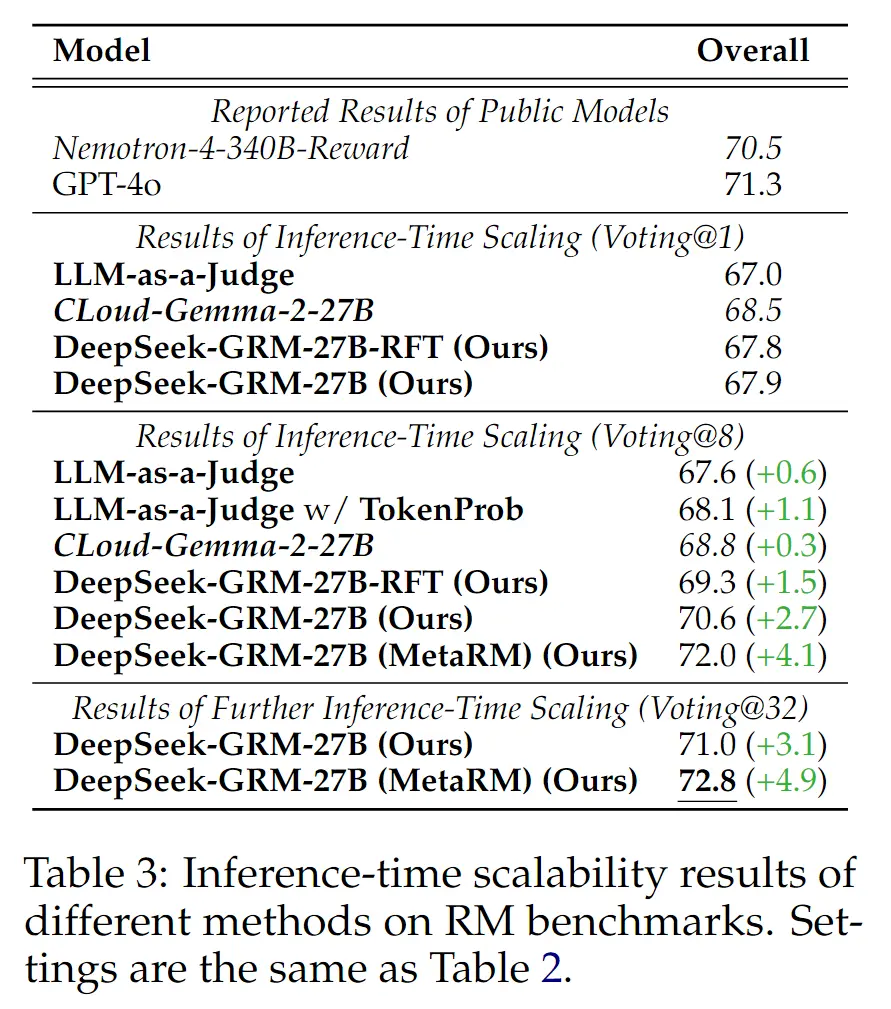
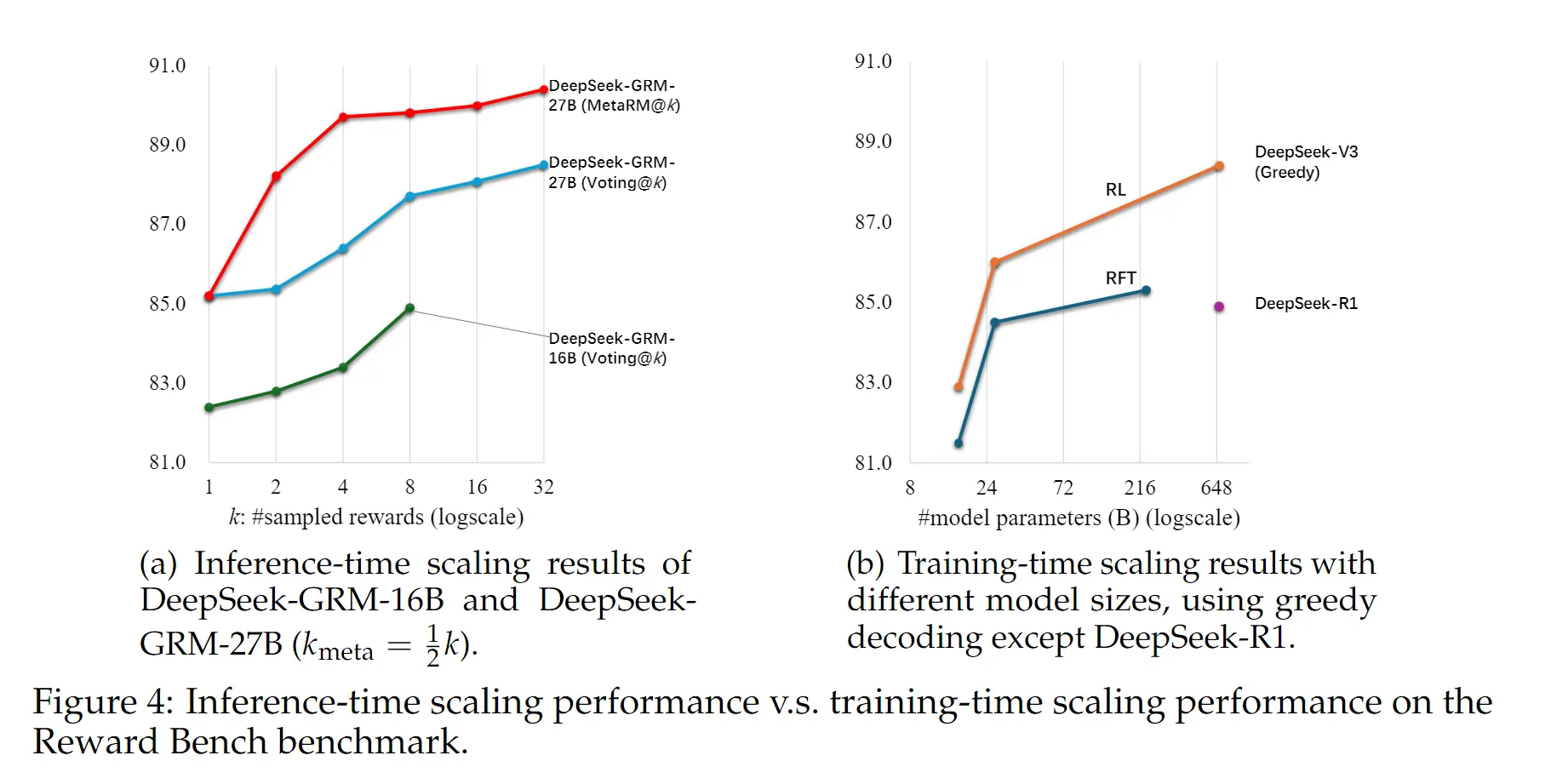
4.3 消融实验
- 各个组件效均有效果提升,其实比较重要的是 Princeple Generation 以及 General Instruction Data(这告诉我们混合通用数据的重要性)。
- non-hinted sampling 更重要,比较合理,给了模型更多的探索和采样空间。hinted sampling 更多是为了防止模型训练过程中学不到东西,是保下线的东西。
- 最终重要的,RL 比 RFT 更重要, RL is all we need(🤣66.1 -> 68.7)。
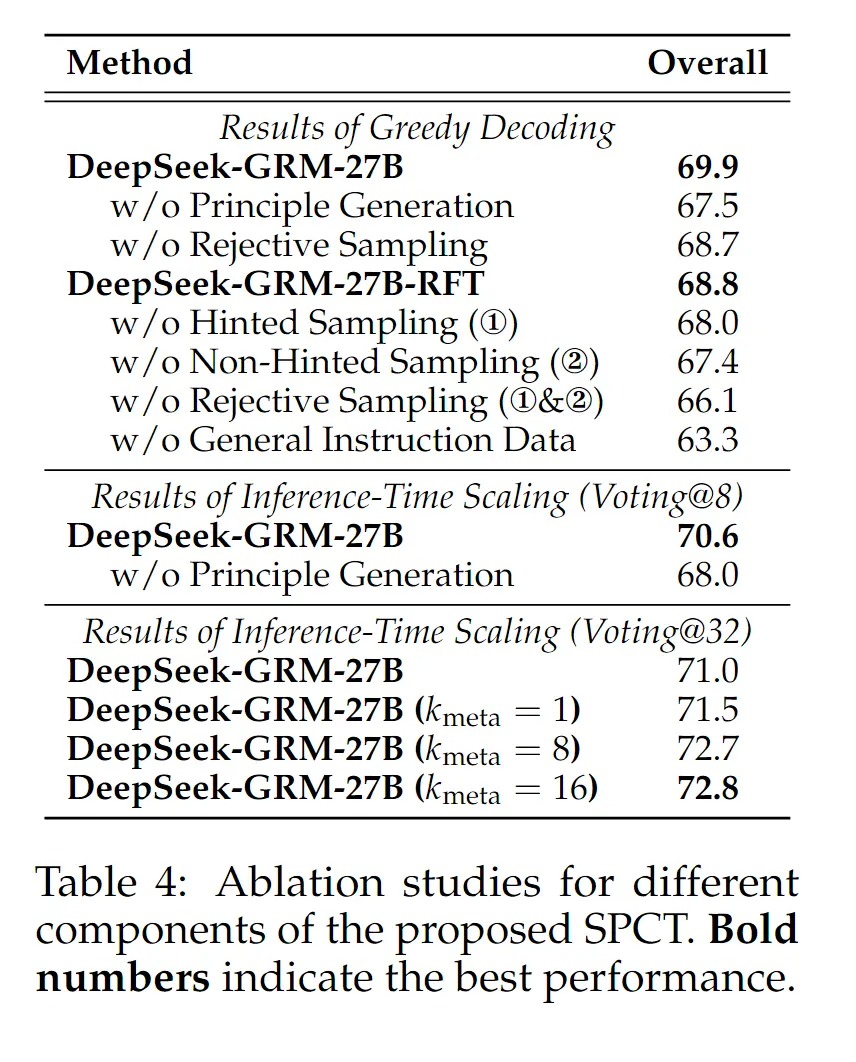
其他
最后欢迎关注我,基本全网同名 chaofa用代码打点酱油
