自顶向下方式深度解读 DeepSeek-R1,内含大量细节
1. 背景
DeepSeek R1 直接在国内火爆出圈,堪比 chatGPT 刚发布时候的势头,大街小巷、各行各业均在讨论 DeepSeek,而这一次 DeepSeek 更是带着中国赢一次,重挫英伟达股价等叙事,更让普通民众自发的传播。
这里我想写一下自己对于 DeepSeek-R1 paper 的阅读笔记,主要介绍一下 DeepSeek-R1 的技术原理与发展路线,但是这篇文章会一改往日风格,不再涉及到任何代码细节,而是从 Top-Down 的思路讲解 DeepSeek-R1 以及 DeepSeek-R1-Zero 的意义。
最后阅读本文之前,需要读者有一定的知识储备。了解
- chatGPT 或者 OpenAI 基本大模型的训练路线
- pre-train -> post-train(SFT -> RLHF),其中 RLHF 通常会有离线在线学习的方式,比如 DPO、PPO等,以及 GRPO 是这一类方式的改进(但是具体能不能真的超过 PPO,并没有定论)
- Scaling Law 值的是什么?
- 在 openai-o1 出来之前,大家一般说的都是 Training Scaling Law。指的是增加 training token, model size and compute budget,就能提升模型的性能。
- 这里以后会写一篇文章讲解
- 在 o1 模型之后,在圈内大火,大家纷纷开始研究 Test-time scaling law 或者 inference time scaling。指的是增加模型的推理过程,就能提升模型的性能。
- 在 openai-o1 出来之前,大家一般说的都是 Training Scaling Law。指的是增加 training token, model size and compute budget,就能提升模型的性能。
- Reasoner 模型是什么?
- 在模型输出答案之前进行长思考,CoT(chain-of-thought) 升级到 Long CoT。
2. 整体框架
DeepSeek-R1 最牛的地方在于它不仅复现出了 openai-o1 模型的效果,同时打破了 chatGPT 以来大家对于大模型训练的整体流程。而其中最重要的认知是:我们只要给模型 accuracy reward,通过 RL(reinforcement learning)的方式就可以提升模型的效果,类似围棋中的 alpha-zero。这样可以极大的帮助模型 Scale,而以往的 SFT 模式,Long-CoT 标注极其昂贵。 那么下面我们就来看看整体的架构是什么样子的呢?
这篇 Paper 一共介绍了三个重要的模型:
DeepSeek-R1-Zero
- 结论是只用 RL 就可以提升模型效果,非常具有启发性。
DeepSeek-R1
- Reasoner 模型很强很强。
- 通过多阶段的训练,相对于只用 RL,可以进一步提升模型效果。
DeepSeek-R1-Distill 的系列模型
- 结论是:在小模型上,在【大模型上进行蒸馏】效果会好于【用 R1 的方式做训练】。
整体架构图(最清晰)来自于 https://x.com/SirrahChan/status/1881488738473357753。
Huggingface 在 DeepSeek-R1 出来之后,立刻开始了复现之路,图片其实也挺清晰的,但是有一些细节上的缺失,但是不影响整体的理解。
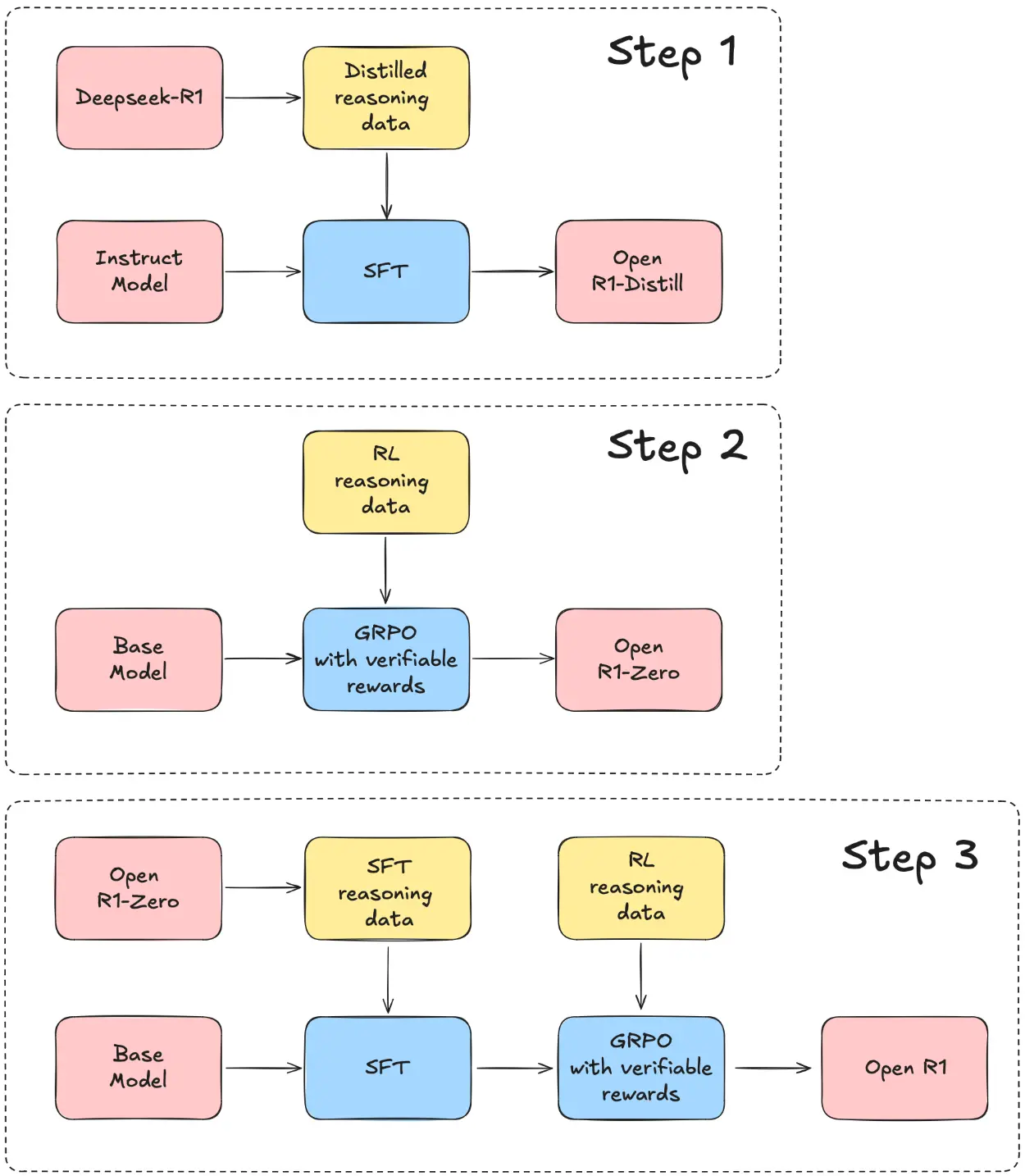
- 在 Step 2 中,如果这个 R1 Zero 想要用于造数据,需要做一些额外的处理,比如 Cold Start Long-CoT SFT 以及在 RL 阶段加入 language consistency 的约束。
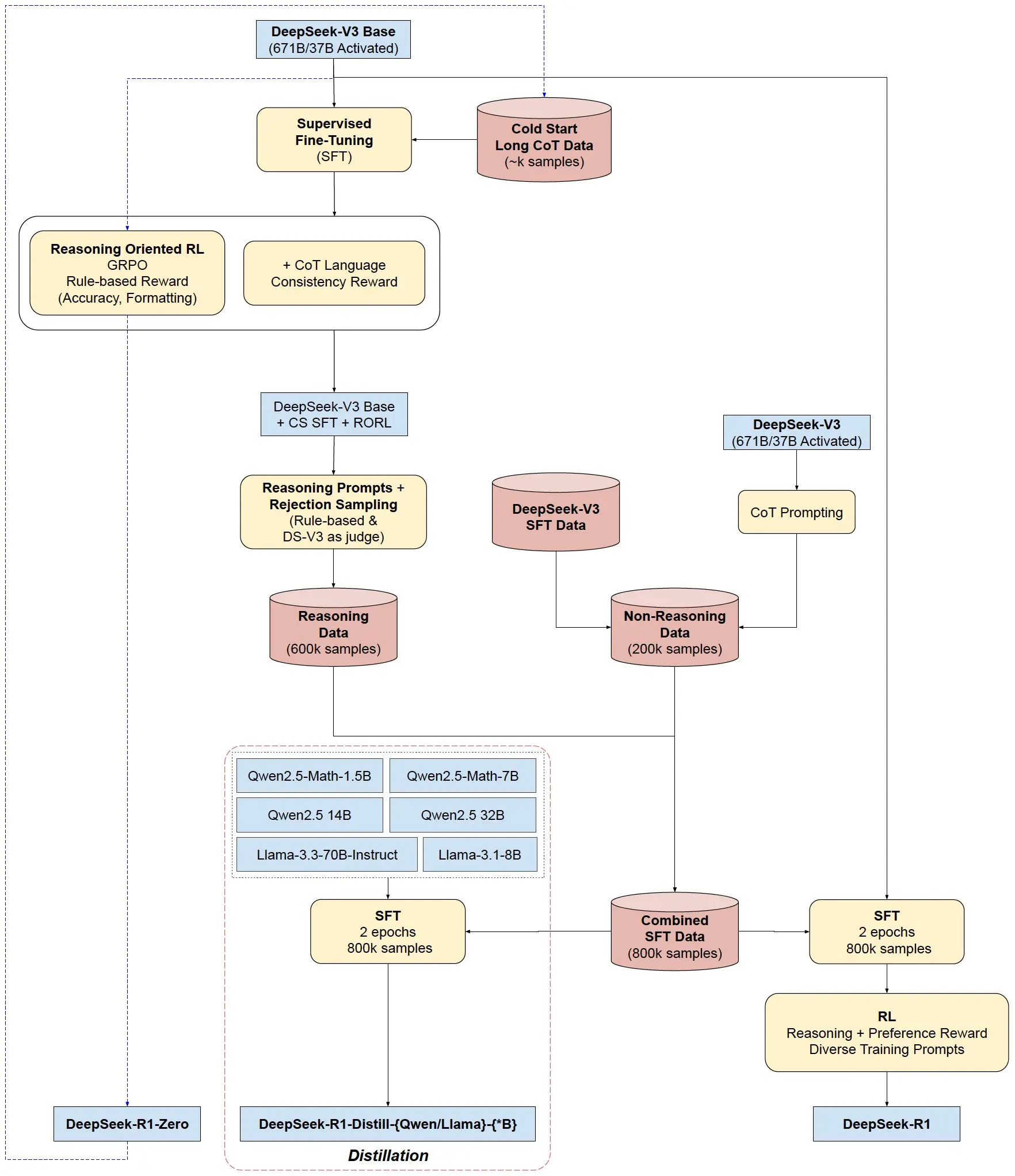
以上是 DeepSeek 整体架构,接下来就来介绍三个不同的模型是怎么训练出来的,以及一些具体的细节。
3. DeepSeek-R1-Zero
一句话解释就是:在 Base Model (DeepSeek-V3)中直接采用强化学习(GRPO,Group Relative Policy Optimization)的方式做模型训练,其中 RL 部分的 Reward 采用的精确的奖励(Accuracy Reward)。
那么具体是怎么做的呢?
3.1 数据构建
 数据构建部分很简单(因为没有透露细节,相比之下 kimi 1.5 的 paper 细节要更多),就是说我们在构建数据的时候,要让模型去回答问题,回答问题的格式要符合以下格式:
数据构建部分很简单(因为没有透露细节,相比之下 kimi 1.5 的 paper 细节要更多),就是说我们在构建数据的时候,要让模型去回答问题,回答问题的格式要符合以下格式:
- 思考的步骤要包含在
<think>思考过程</think>。 - 最终的结果要包含在
<answer>最终结果</answer>。 - 并且需要让模型先思考,然后再问题。
那么这部分数据哪里来的,paper 没有透露太多,但是一些公开的实践和复现中,大多都采用 math 和 code 相关的数据集,因为这些数据具有标准答案,我们完全知道最终的结果是正确还是错误。
备注:这里 DeepSeek 并没有介绍数据怎么筛选的,以及各种配比,以及哪种好,哪种坏
3.2 强化学习
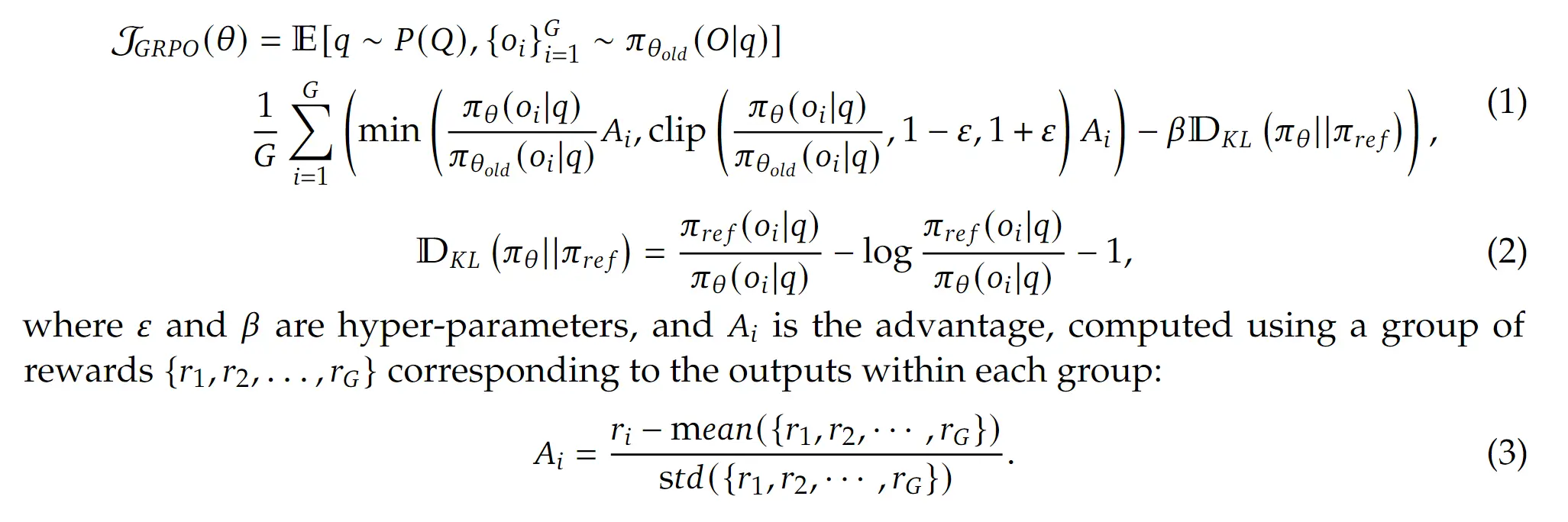
相对于常见的 DPO、PPO,DeepSeek 采用的强化学习算法是 Group Relative Policy Optimization (GRPO),关于 GRPO 算法原理的核心解读准备下一篇文章来写。
核心的优势我个人觉得是
- 减少了 value/critic model,这样可以节约资源,方便 scaling。
- 也许一定程度上减少了 Reward hacking。(依然有争论)
而在这一步强化学习中,DeepSeek 采用的奖励有两种:
- 最终结果的精确奖励。模型最终输出的答案是否正确。
- 中间格式的格式奖励。模型是否先输出
<think>xxx</think>,然后输出<answer>xxx</answer>这样的格式。
3.3 核心启发
- 第一点当然是毫无疑问的,模型效果很好,并且是出人意料的好,这证明了【仅仅是通过 RL,没有 SFT】就可以让模型的推理能力提升到一个不可思议的水平,此前没有人复现 o1 的效果。
- 第二点,模型在 RL 的模型,具有明显的进化效用。随着 RL 的训练步数越来越多,效果越来越好。
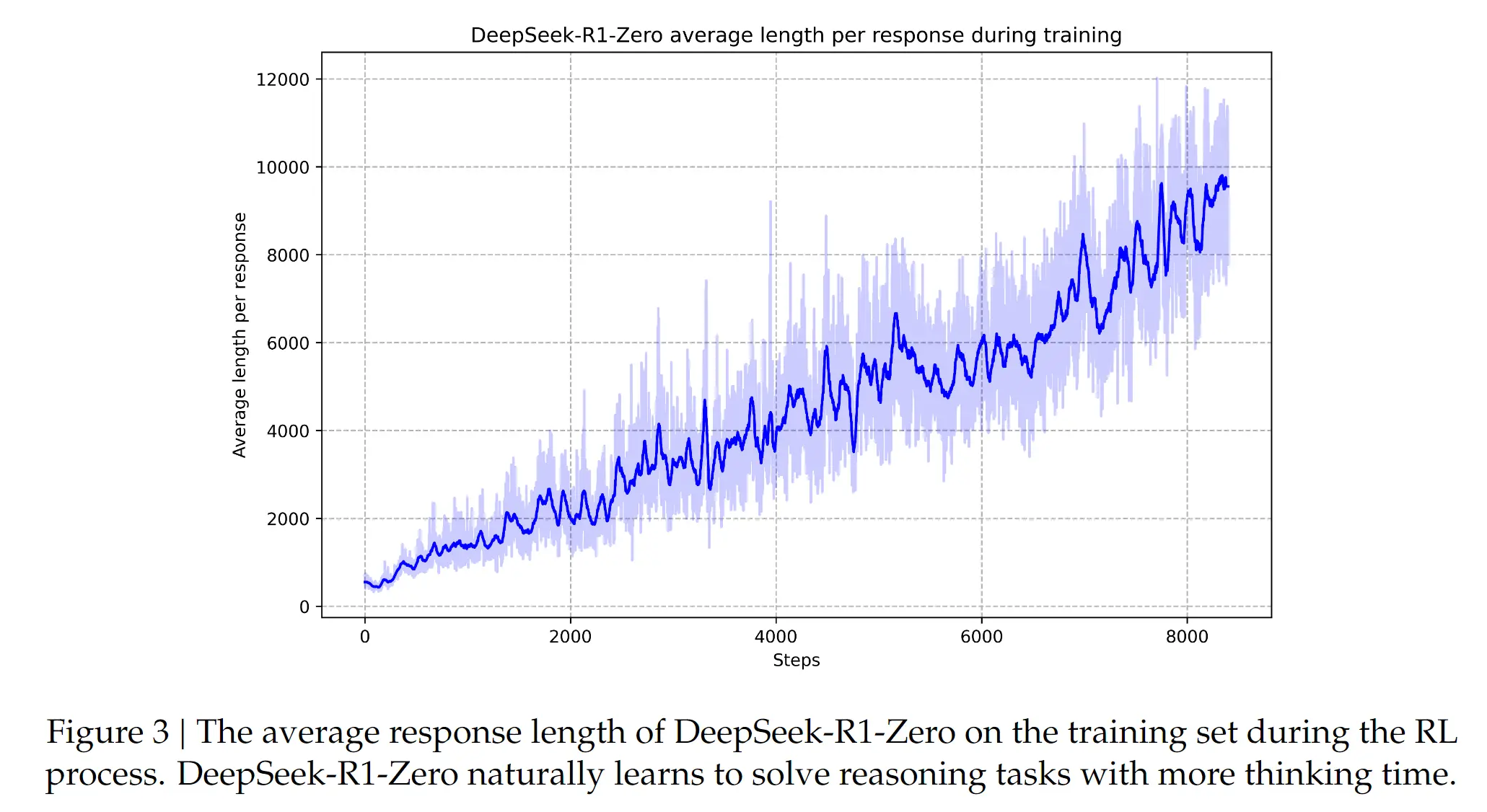
- 第三点是,模型在 RL 的催化下自我进化的能力。具体是指:越训练,模型的思考越长,输出的 token 越多。模型会在中间的思考过程中出现【反思、纠正、重新评估、重新探索】等行为增强模型思考和解决问题的能力。
- 第四点,模型会在训练的时候产生顿悟能力,指的是:模型会给一些重要的步骤一些标记(flag),给更多的思考和评估的token。但实际上我觉得和第三点是类似的,他们本质上都是可以回顾以往的输出以及探索新的可能。
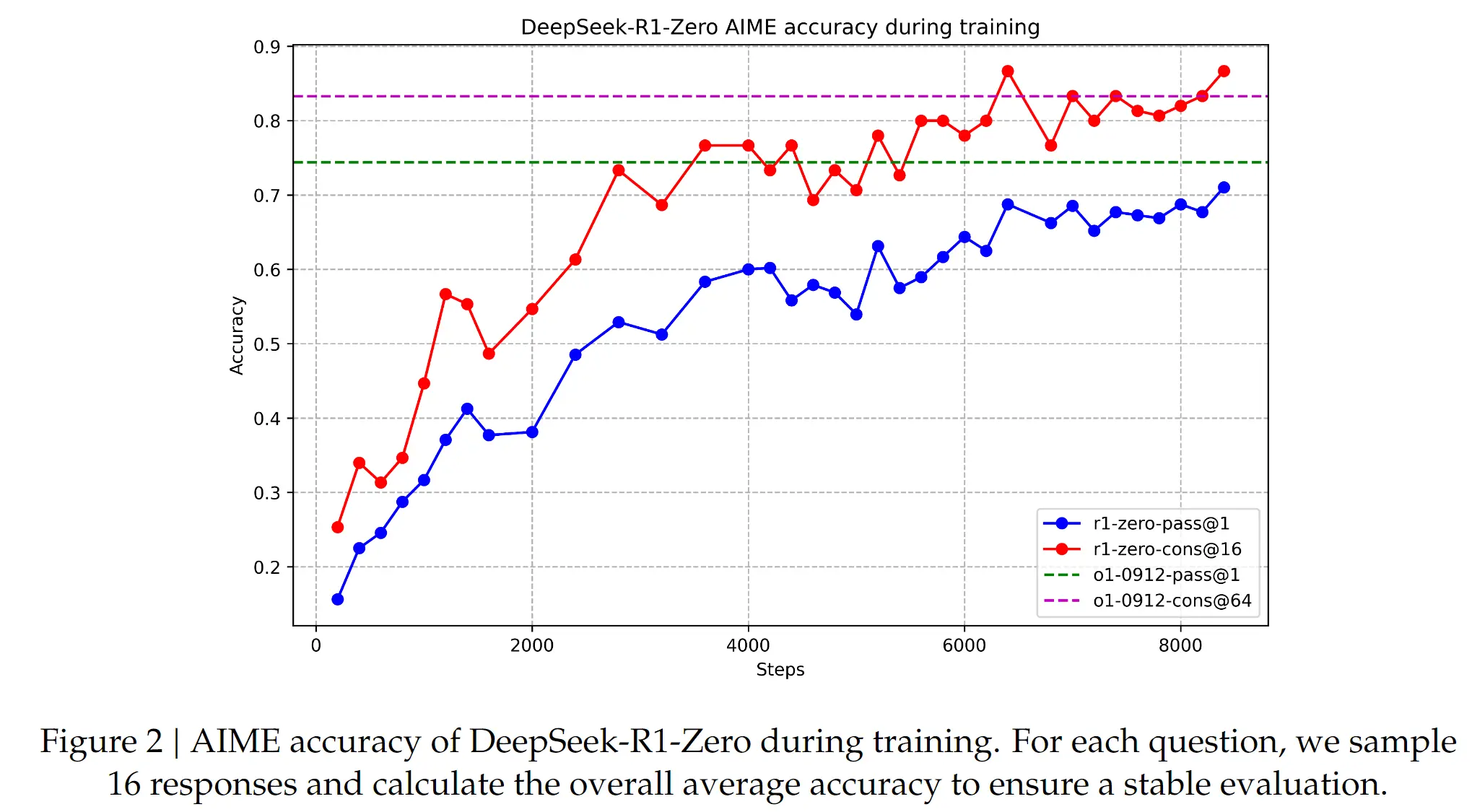

但是 R1-Zero 也不是没有任何的缺点,它的回复(思考过程)会出现两个问题
- 可读性很差。可能会输出一些人类看不懂的东西。
- 语言混合。一会中文、一会英文、一会阿拉伯文等。
4. DeepSeek-R1
那么为了改进上面的问题以及进一步优化效果,我们继续看一下 DeepSeek-R1 是怎么进一步优化的呢?请一定先阅读整体架构图,然后再跟着目录结构一步一步的深入。
4.1 冷启动
刚刚我们提到,模型可读性问题,假设这个模型叫做DeepSeek-r1-zero-no-coldstart,因此我们可以设计一个冷启动方式去现训练一个 DeepSeek-R1-zero-with-coldstart。
具体做法是我们可以
- 找一部分 long-cot 的数据作为 few-shot,通过
prompt engeering让模型生成具有反思和验证的回答(本质上也是 long-cot), - 还有收集
DeepSeek-r1-zero-no-coldstart产生的结果(这部分结果要通过人工标注修改、过滤)。
备注:这里的表述感觉比较微妙。我们并不清楚这里是两部分数据,还是说都是通过人工修改
DeepSeek-r1-zero-no-coldstart产生的结果,以及对应的比例。但我倾向于这是两部分数据。一部分是其他模型产生,一部分是DeepSeek-r1-zero-no-coldstart产生。
假设我们收集到了这样的 coldstart 数据,我们还会从 deepseek-v3-base 中作为 SFT 的训练起点,然后得到了一个 DeepSeek-v3-base-with-coldstart-sft 模型。这部分数据具有两个优点:
- 可读性。这里又有一个细节比较含糊。文章里提到,coldstart 数据设置成了
|spcial_token|<reasoning_process>|special_token|<summary>,但是前面我们已经知道了DeepSeek-r1-no-coldstart产生的数据是<think>思考过程</think><answer>最终结果</answer>格式,为什么这里又要设计一个新的格式?- 我的思考:上面的 reasoning_process 对应
DeepSeek-r1-no-coldstart格式中的【思考过程】,special_token 对应<think>xml,而summary部分可能是其他模型(比如 deepseek-v3-instruct 产生的结果。如果summary 部分效果比较好,那就说明了 【思考过程】是可读的。因此保证了 coldstart 数据 reasoning_process 的可读性。- 如果有其他的理解,欢迎评论区留言指教
- 我的思考:上面的 reasoning_process 对应
- reasoning 能力更高。因为 coldstart 做了一次人工筛选,相当于做了潜在的人类偏好对齐,因此相对于
DeepSeek-r1-zero-no-coldstart,观察了更好的效果。
备注:这里为什么要设计两个格式,这两个格式有什么区别,以及 summary 是怎么来的,以及 coldstart 数据是怎么来的,都没有讲得很明确。
4.2 聚焦 Reasoning 能力的 RL
这个步骤是想要聚焦提升模型的 Reasoning 能力。我们采用和 DeepSeek-r1-zero-no-coldstart 一样的 RL 训练方法,目前是为了产生deepseek-r1-zero-with-coldstart-focus-on-reasoning但是有一些改进。
- base 模型替换。从
deepseek-v3-base换成了DeepSeek-v3-base-with-coldstart-sft。也就是上一步生成的结果。 - 奖励内容做了替换。
DeepSeek-r1-zero-no-coldstart用的是【格式奖励】和【最终结果奖励】。- 而
deepseek-r1-zero-with-coldstart-focus-on-reasoning采用的是【语言一致性奖励】和【最终结果奖励】。- 但实际上加了【语言一致性奖励】会略微降低模型的性能。
这里我们得到一个推理能力很强的模型 deepseek-r1-zero-with-coldstart-focus-on-reasoning,它是用来干嘛的呢?答案是:【用来为最终的 deepseek-r1 产生推理训练数据】。
4.4 拒绝采样和SFT
从这一步开始,我们正式的为训练 deepseek-r1 做努力了,因此我们的目标不仅仅是 reasoning 能力了,而是全场景都要有好的效果。因此我们的数据自然是需要【推理数据】以及【非推理数据】。
4.4.1 推理数据
这里我们收集数据的时候,我不再采用 rule-based rewards 了,而是用 deepseek-v3 作为一个 reward-model,评判模型的生成效果的好坏。此外,这里还会把语言混合、具有长段落和代码块的 CoT 样本过滤掉。
具体做法是:先让 deepseek-r1-zero-with-coldstart-focus-on-reasoning 对每一个样本生成多条结果,然后用上面两个方式进行过滤,选择其中一条结果,最终得到了 600k 的推理数据样本。
上面的筛选过程就是拒绝采样。
4.4.2 非推理数据
所谓的非推理数据就是:写作、事实问答、角色扮演、翻译等任务。这里是直接采用了 deepseek-v3 的部分SFT数据。对于特定的任务,会用 deepseek-v3 产生 CoT 过程,然后再给出答案;而对于简单的问题,则省略了 CoT 的过程。最终一共收集了 200k 的非推理数据
备注:哪些任务要有 CoT 过程,哪些算是简单问题以及比例是多少,这些都没写
现在我们一共得到了 800k 的 SFT数据,然后把它们用 SFT 训练两个 epoch。
4.4.3 全场景的强化学习
为了进一步使模型与人类偏好保持一致,我们再用一个二阶段强化学习作训练,旨在提高模型的有用性和无害性,同时细化其推理能力。这里有一些小小的细节。
- 对于推理数据,我们还是和
deepseek-r1-zero一样,采用规则奖励的模型作奖励信息训练。 - 对于非推理数据,我们采用
reward-model作为奖励信号,这是为了捕获细微场景的人类偏好。- 我们知道这里的强化学习其实和传统的强化学习比较类似,我们的 reward model 会评估模型的不同的方面,或者说我们有多个 reward model。
- 有用性上我们只关注最终结果的有用性和【与问题的相关性】,这样可以减少对于推理能力的干扰。
- 无害性上,我们则关注整体的推理过程和最终结果。
- 我们知道这里的强化学习其实和传统的强化学习比较类似,我们的 reward model 会评估模型的不同的方面,或者说我们有多个 reward model。
最终,通过这种混合的奖励信号和不同的数据分布,我们得到了最终的deepseek-r1,在推理上能力很棒,同时保持了有用性和无害性。
4. DeepSeep-R1-Distill-Qwen/Llama-xB
有一个直观的想法是,小一点的模型能不能得到类似的 deepseek-r1 的能力。有两种方式:
- 方式1:直接用 deepseek-r1 蒸馏数据,让小模型学习(SFT)。
- 方式2:小模型采用
deepseek-r1同样的 pipeline 作训练,获得这样的能力。
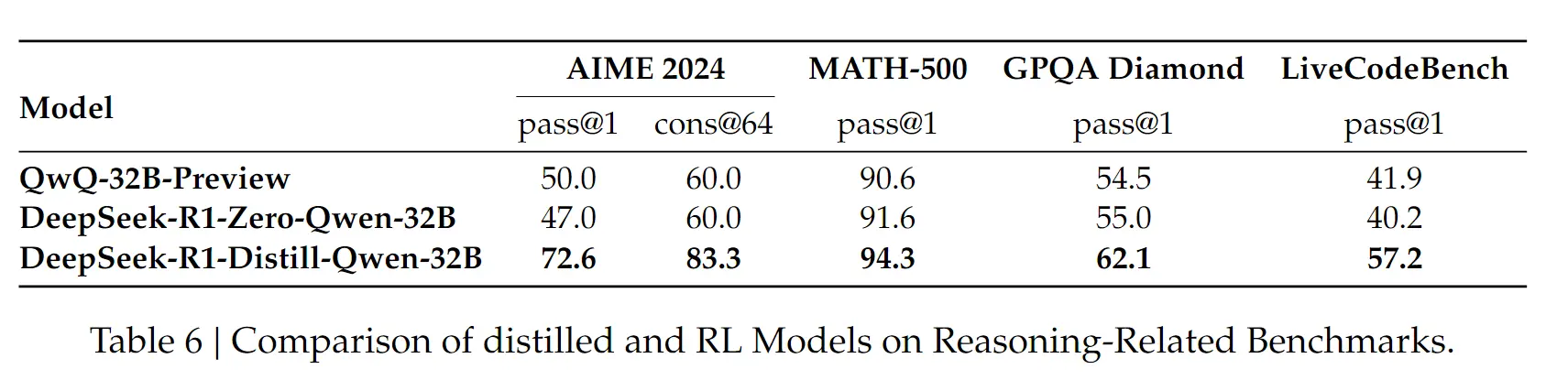 从最终的结果看,蒸馏的效果好于直接用小模型作RL训练。但是这里有一个小的发现,
从最终的结果看,蒸馏的效果好于直接用小模型作RL训练。但是这里有一个小的发现,qwq-32b-preview 效果和 deepseek-r1-zero-qwen-32b 基本同一水平,因此 qwq 也很有可能是采用了类似的方式作训练。
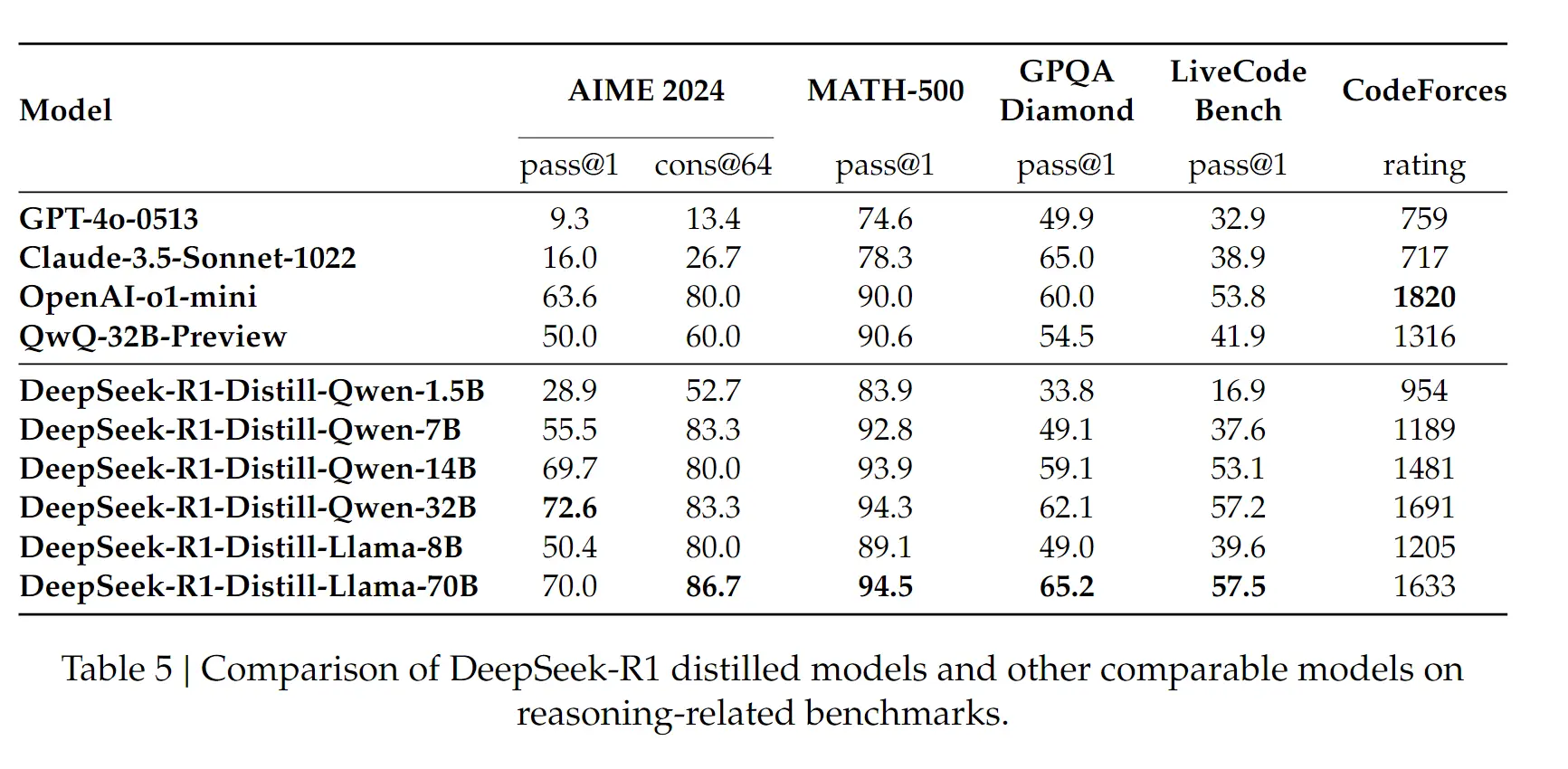 此外,从蒸馏的结果看,模型的推理能力得到了巨大的提升,这说明了什么?
此外,从蒸馏的结果看,模型的推理能力得到了巨大的提升,这说明了什么?
- Long-cot-with-reasoning 的蒸馏能够让小模型进一步提升推理能力。
- 业务上在使用小模型具有了更多的可能性,赶紧学着 R1 的脚步用起来吧。(似乎看到了一点点小模型的希望)
5. 一些失败的尝试
- Process Reward Model(PRM)
- 定义一个 PRM 的粒度很难,怎么算是一个 Step 呢?
- 评估当前的 Step 是否准确很难
- 训练一个 step rm 很难,容易产生 reward hacking
- Monte Carlo Tree Search(MCTS)
- 在语言模型中,词表太大了,基本都十几K,因此搜索空间太大了。
- 如果采用最大的探索限制,又容易产生局部最优。
- value model 很难训练,不好评估当前的步骤是否是好的。
但是这些失败的尝试不代表这些路径就是错的,也许是还没有找打正确的打开方式。
其他
最后欢迎关注我,基本全网同名 chaofa用代码打点酱油
